Hello,
I would like to start by thanking TI for all the documentation and examples it provides for its customers. We also found the forum very helpful most of the times.
We are developing our project on a TMS32C6748 for a realtime application. We run into a problem with interrupt latency which we cannot find an apparent reason/solution.
Let me first, describe in brief the design and implementation of the system :
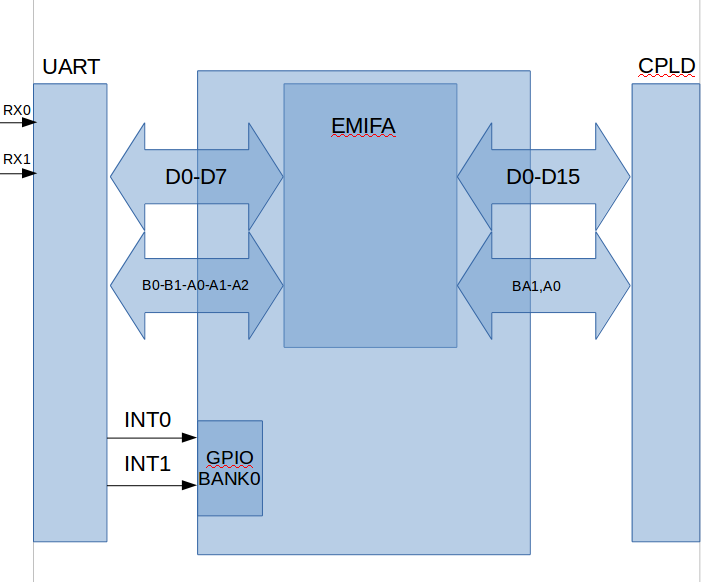
The DSP is connected to a 5 MegaBaud Dual Channel Uart ( 64 bytes FIFO, programmable trigger levels, multiple status/config registers )
Via Emifa ( 48Mhz speed, CS4 memory space, Asynchronous, 8 bits mode, and timings according to the datasheet of the uart chip)
and also, 2 interrupt lines connected to GPIO Bank 0 (1 and 2 ).
Functional design :
Each millisecond, the DSP receives a total of 192 bytes per channel, divided into 3 packets of 64 bytes (the fifo maximum capacity), which takes 180 microseconds, spaced by 100 microseconds ( to give time to the CPU to service the interrupt)
For the sake of simplicity, lets call the received bytes from both channels a 'data sample'.
The DSP is supposed to run an algorithm on 2080 samples which uses among other things, DSPlib, MathLib.
Implementation :
In order to maximize CPU usage, Servicing the interrupt is done by an ISR to check the Status registers, which will later trigger manual EDMA3 event to buffer the incoming data into a ping pong fashionned way and feed it to the algorithm which is supposed to run in the main program.
We are running the board at 456Mhz through Code Composer 7, an XDS100v3 and C6748 Starterware 1.2.4 . The code is linked to run from DDR2 with L2 Caching Enabled.
Result :
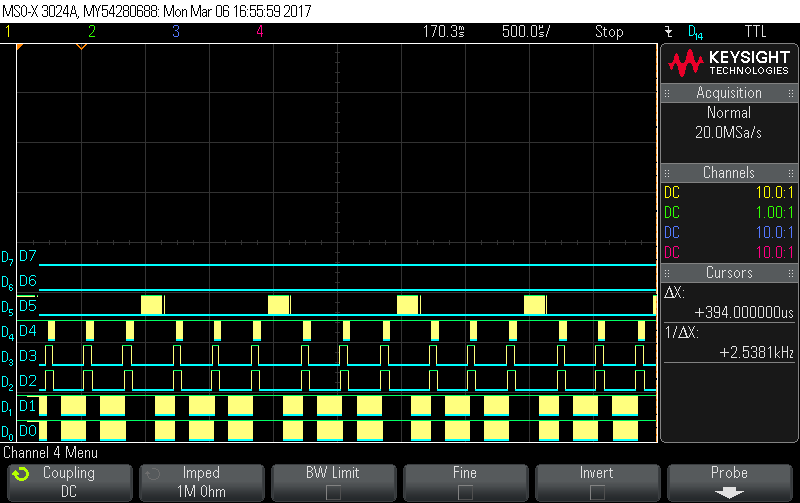
after each 64 byte chunk, the interrupt line goes high and then CS4 starts toggling which illustrates the ISR handling and the EDMA3 read. They both work fine and gives us the expected results.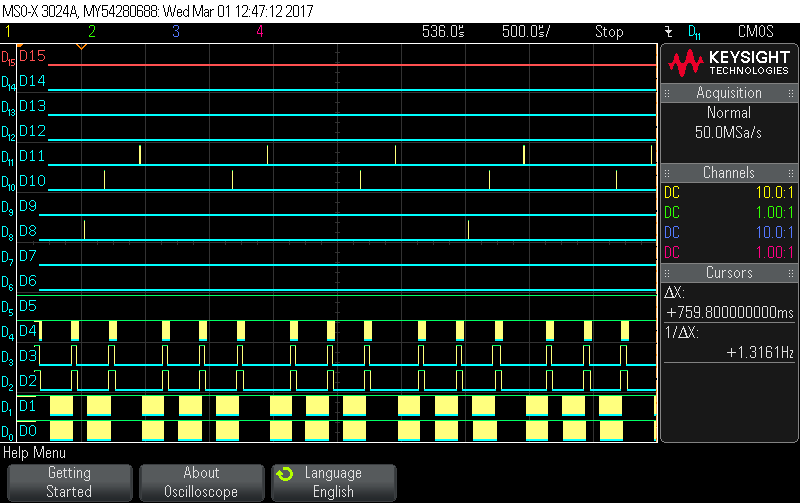
D0 : Uart Channel 0 incoming data
D1 : Uart Channel 1 incoming data
D2 : Uart Channel 0 Interrupt Line
D3 : Uart Channel 1 Interrupt Line
D4 : Emifa CS4
The Problem :
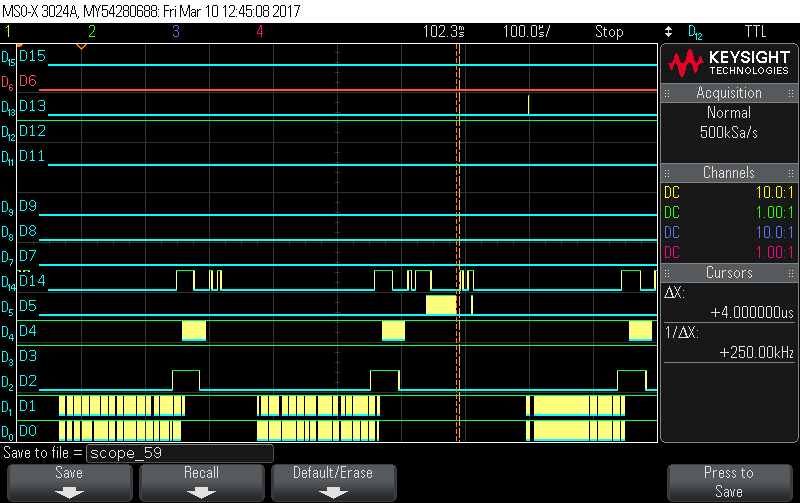
It occured when we started feeding the buffers to the algorithm, whereas, we buffer 2080 samples into a "PingBuffer" (which has the size of 1MB) and we pass it to the algorithm which is running in the main loop. We start filling in the "Pong buffer". Everything keeps working fine until a certain point in time, the ISR gets delayed abnormally and we lose synchronization and therefore, we dont meet our deadline.
The following snapshot illustrates this behaviour.
We read through the forum and most of the manuals available to us and we came across multiple possible reasons for this :
First, the interrupts could be disabled by the compiler. We recompiled all the code used, starting from ours, to the C standard library, Mathlib and DSP lib with --interrupt_treshold = 1. We looked into the assembly output and the "DINT" instructions is never used ( except for some assembly files in mathlib, for which we tried both commenting DINT or reimplement the functions used in C.)
Second, We looked into BUS contention for the mDDR/DDR2 Controller. since the gel File is doing the initialization for us, the default value of the PBBPR was 0x20 which we decreased to 0x10 without any effect on the problem.
Third, Since the CPU does not allow nested interrupts in hardware, we made sure that we only program the Uart interrupt (for test purposes only)
Forth, The current configuration of the master peripheral registers gives higher priority to the used DMA Controller (which is both the default, and desired configuration).Giving a higher priority to the CPU, doesnt change anything in the this delay.
Now that we have tried all these, we started to suspect that it is a caching problem. Could cache misses in L1P cause this long delay ? If So, what can we do about it?
EDIT : we tried linking the algorithm text section into DDR2, and all the rest in L2RAM space and we got the same result.
We are also open to any suggesttions to help us with our issue.
Thank you in advance.
Regards,