Tool/software:
I checked the TI forums but could not find a definitive solution so am posting a new question.
I have a problem with the ADS7038 chip. I seem to get wrong ADC values every now and again. This happens on my production card but I have also recreated it with just an NXP S32K146 development board talking to a TI ADS7038 development board. I believe it might be an SPI clocking issue.
I have some oscilloscope JPGs and CSV readings that show interesting/weird effects. These come from my production card but I will aim to get some traces from the NXP/TI combination to eliminate our production card design from the equation. This will take a few days.
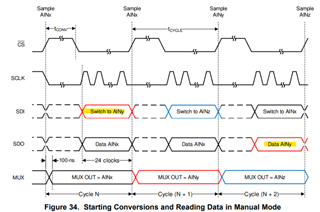
I am reading from ADC channel 3, with the channel number appended, so in the 24 bit MISO return from the ADC I should be getting 0xABCd00 where 0xABC is the ADC value and d is the channel number (3).
I inject a sawtooth input from 1V..2V at 1Hz and/or 1KHz. I have AVDD set to 3V. This should mean that I expect values in the range 1300..2730.
I send a WRITE, CHANNEL_SEL, 3 and then a WRITE, SYSTEM_STATUS, 0 and get the ADC reading on the 2nd command. I then repeat this sequence (currently as fast as possible, but it also fails when run at a fixed frequency - where the original problem was found).
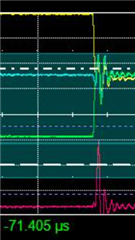
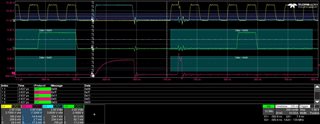
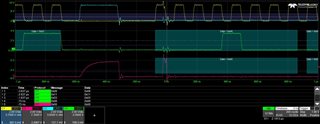
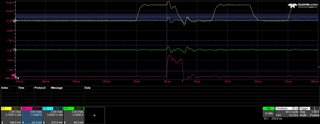
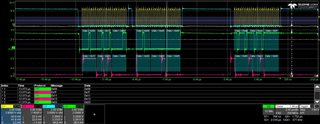
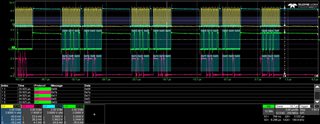
I have modified my code so that if I get a non-3 channel number or ADC reading < 100 or ADC reading > 3700 then I send an (invalid) SPI message 0xDDEEFF and halts at a breakpoint. I have the oscilloscope stop recording when it sees this 0xDDEEFF value.
Ideally the code should never hit the breakpoint and the oscilloscope should never stop recording. Unfortunately neither is the case as shown in the JPGs.
The JPGs, especially the final one, show ADC readings increasing (due to the sawtooth input) 0x7cc, 0x7e1, 0x7f1, 0x000, 0x80c (the 0x000 is the erroneous value).
Interestingly on the 0x000 there is an attempt by the ADC to drive a HIGH bit but it lasts less than one clock pulse.
I also have the recordings in CSV files for the 4 channels (C1 = CLK, C2 = MISO, C3 = CS, C4 = MOSI) if that helps.
When I first observed this problem (before I had scope traces) I thought it always happened around 2048 (which is half of the 4096 12-bit ADC max range). In the attached JPGs the problem looks like the ADC trying to start with a 1 (implying ADC >= 2048) which would support the "it happens around MSB=1 (ADC approximately 2048)". However, further tests with a sawtooth in the range 0.5V..1V (so nowhere near 2048 ADC) also had issues. It might be a factor but not the full story.
I am using defaults for most of the registers, specifically CPOL/CPHA are both 0. Channels 1 and 3 are set to ANALOGUE INPUT with all others set as GPIO INPUT. When I used the NXP/TI development boards I had all channels set to 0V or 3V, except channel 3 which had the sawtooth.
During other tests I noticed the following
- Erroneous channel number (usually double the required channel), i.e. channel 6 instead of 3.
- Sometimes I also got channel 0 but less often than getting double the required channel.
- I also did some READ, REGISTER, 0 and got back what looked like ADC readings (2 bytes of ADC/channel value then 0x00) rather than a register read (1 byte of register value, then 0x00 0x00).
In the READ, REGISTER, 0 returning an ADC reading I am guessing that the ADC did not interpret the command correctly so rejected it and therefore outputs the latest ADC reading. If the underlying problem is a clocking issue then this would make sense and is just the reverse of me seeing a doubled channel number.
Are you able to shed any light on this problem? Do the JPGs and CSV files help?
Thanks
Darren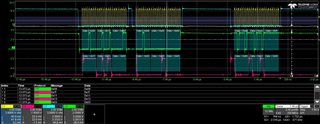
 Z2--got you 1--00001.csvZ3--got you 1--00001.csvZ4--got you 1--00001.csvZ1--got you 1--00001.csv
Z2--got you 1--00001.csvZ3--got you 1--00001.csvZ4--got you 1--00001.csvZ1--got you 1--00001.csv