


Other Parts Discussed in Thread: AM3352
Hello,
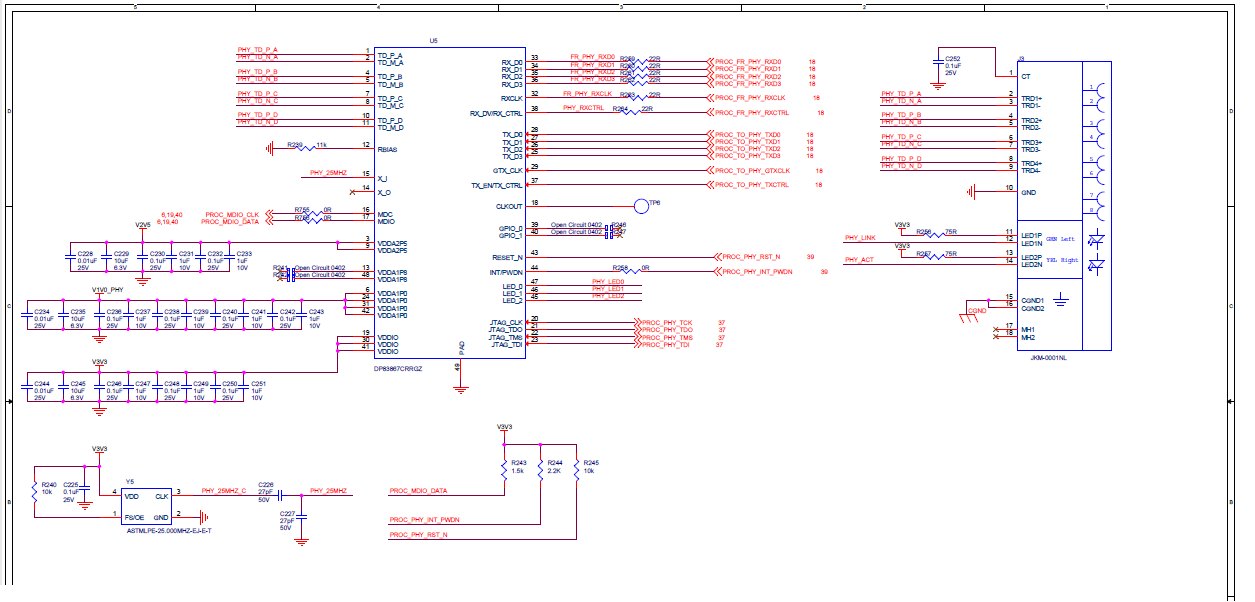
We have a custom board with two TI DP83867 PHYs and a 3rd party switch chip sharing the MDIO bus. We are seeing some intermittent behavior where one of the TI PHYs will go into a bad state and lose the link to the network. When this happens, if we do a dump of the MDIO registers for this PHY, all registers show 0xFFFF values. (Occasionally, we will see all registers show 0x1140 instead of 0xFFFF). When the error occurs, we have to reset the phy or power cycle the board to recover. I have discovered that if I put the second phy in power down state, the first phy no longer experiences these errors. I've been probing the MDIO signals with a scope, and I see that sometimes there are data transitions on the mdio bus that violate the hold time of the phy. Looking at the data sheet for dp83867, I found the following timing parameters:
7.8 MII Serial Management Timing(1)
See Figure 3.
PARAMETER MIN NOM MAX UNIT
T1 MDC to MDIO (output) delay time 0 10 ns
T2 MDIO (input) to MDC setup time 10 ns
T3 MDIO (input) to MDC hold time 10 ns
T4 MDC frequency 2.5 25 MHz
It looks like the clock to data delay time for read data returned by the phy will be between 0 - 10 ns. But, the required hold time is a minimum of 10 ns. If we have two DP83867 phys sharing the same mdio bus, will the output of one phy violate the timing parameters of the other phy? On the oscilloscope, I am seeing clock to data timing as small as 5 ns. I've confirmed that the data transitions with ~5ns delay are coming from the DP83867's. Also, disabling the second phy will result in the first phy not experiencing the error. So, I am suspecting some interaction between the two phys.
Given the timing numbers above, is it ok to have two DP83867's share the same MDIO bus?
Thanks,
Gavin.


{kind=link}
{kind=link}