


Hi all,
This is a shot in the dark because I am stumped debugging a random hard fault that is happening in my code.
This fault occurs seemingly randomly, sometimes days in between or sometimes even months. I have tried catching the fault while in a debug session with a JTAG attached but have had no luck for months. So I don't have to sit next to the micro with a debug session going and a JTAG attached, I have added some register information that I save to flash in my fault handler. Not the most sophisticated way to do it, but I was hoping I could reverse engineer the problem once I could observe the register stack.
I have gotten a few crash dumps and have started picking apart the register meanings, but I am thoroughly confused by what I see. I wont list everything here, but the important registers I see are as follows:
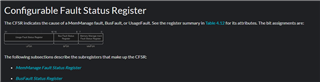
The CFSR register has a value of 1. This tells me that an access violation has occurred (IACCVIOL). When I first started doing these crash dumps, the registers were telling me that it was an "imprecise fault" which means a lot of the information in the registers is useless. After googling, people suggested to turn write buffering off to turn imprecise faults into precise faults. I did this and that is how I found that it was an access error.

At this point I was excited because the documentation for IACCVIOL states "When this bit is 1, the PC value stacked for the exception return points to the faulting instruction. The processor has not written a fault address to the MMAR." Great, I can look at the PC value, which I also wrote to flash, and can narrow down what instruction is causing the problem.
The problem is, the PC value that is in the register stack in the fault handler is the value "0xFFFFFFEC". This value has consistently been in the PC register for multiple crash dumps. I am at a loss because this address is 19 bytes away from the end of the TM4C123 chip memory itself. It is also firmly in a "reserved" area of memory.
From datasheet:

While I agree that trying to access this memory should generate a fault, as it is reserved. Am I wrong in interpreting the documentation as saying the instruction that caused the fault is at the PC value. What program instruction could possibly be at 0xFFFFFFEC? I am open to the possibility that maybe the value in the PC is garbage, but from reading the ARM register documentation, it seems like it specifically calls out "When this bit is 1, the PC value stacked for the exception return points to the faulting instruction"
Any advice, ideas, or thought is much appreciated. The address being in a chunk of reserved memory almost at the end of the chip is really throwing me for a loop:)
Thanks!

