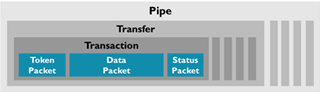
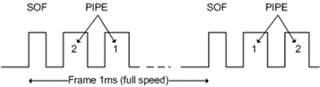
Hello,
While reading the datasheet about the USB controller in device mode I noticed there is 4k of ram/fifo allotted to the endpoints as well as a single buffering/double buffering mode. I'm attempting to use bulk transfers to use the maximum allowable amount of free bandwidth when the bus isn't busy for data transfers. This yields increased throughput for packets as bulk transfers can send more than a single 64 byte packet per frame. So long story short I want to use bulk so I can get the best throughput on the MCU for USB 2.0 device mode.
With all that said I've become concerned and have a few questions.
1. The datasheet/UG states there is 4k of fifo space allotted for endpoints. Does this mean all active endpoints will share this ram or each endpoint can have its own 4k buffer if desired?
2. The double-buffering mode as described in section 18.3.1.2 and beyond implies that you can only load 2x packets (two 64 byte chunks) into the endpoint buffer. Does this mean I'm bandwidth limited to sending 2x bulk packets per frame? This seems quite poor as the purpose of bulk is to send (I think) around 19 packets if there is enough unused bandwidth in the frame? I feel like I'm missing something as this would only really be throughput improvement of 2x HID which is quite slow.
3. Depending on question #2 above - is there a way to load many packets into an endpoint fifo so max utilization of bulk is possible (of course depending on the bus)? My understanding, from the host side, is that if there is space the host will continue to grab more packets for the current transfer and the device must make sure those packets are immediately available. This is important because (I think) the MCU is unable to get in interrupt to fetch the extra data for that frame if there is available space - from my research it seems like the additional packets must be in the fifo.
Any help is greatly appreciated!
Thanks!