Other Parts Discussed in Thread: BQSTUDIO
Hi,
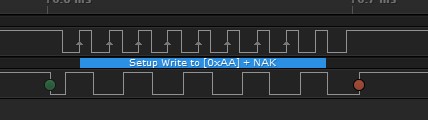
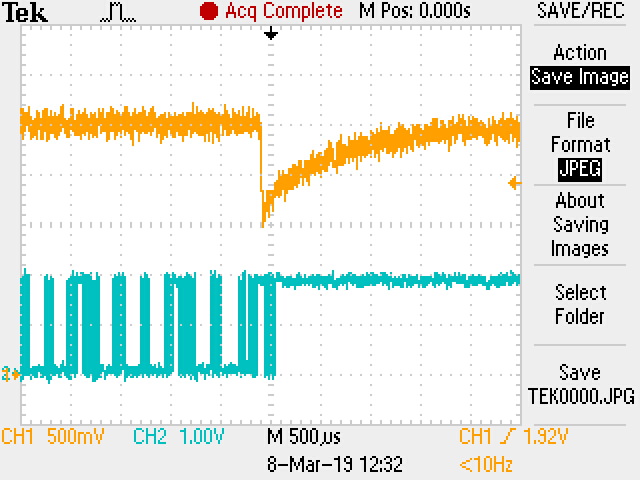
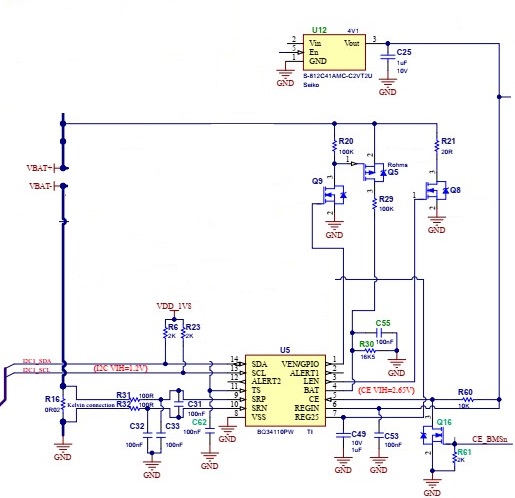
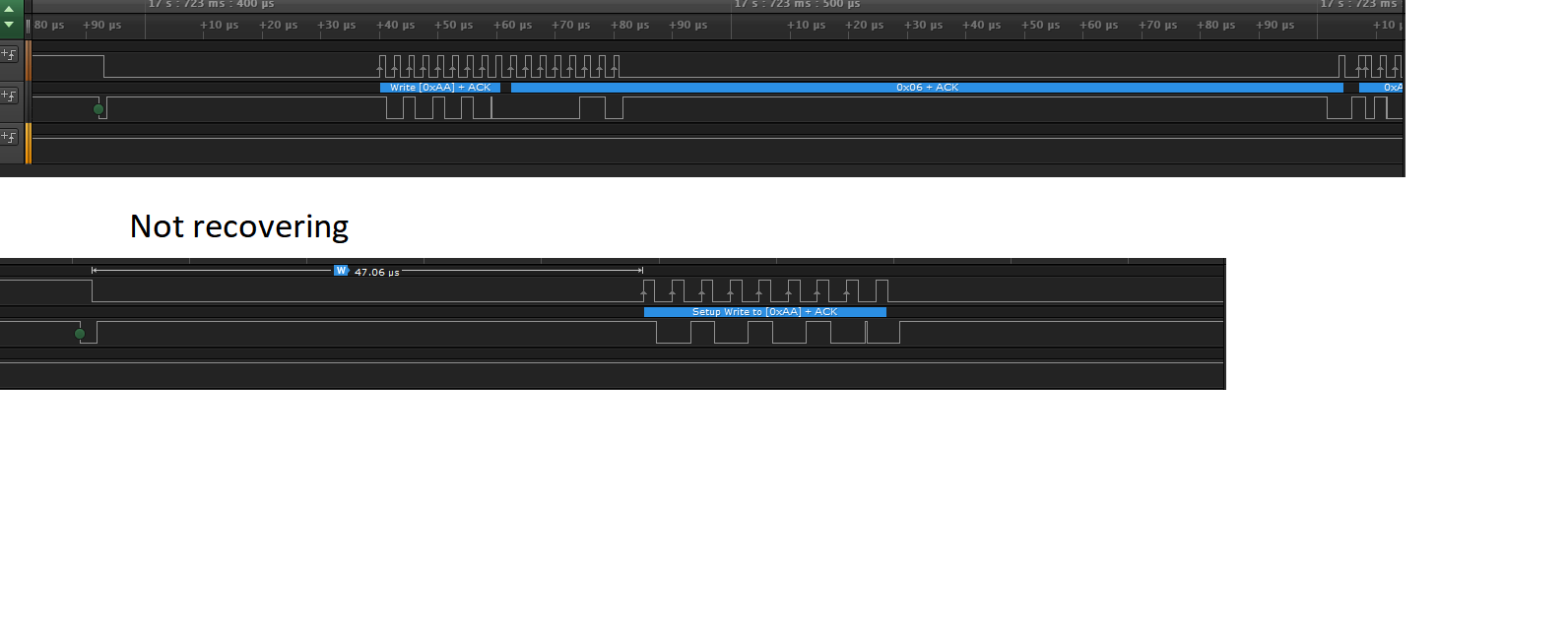
We have a rare occurrence of I2C timeout and we have a timeout set at 10ms for a 100kHz I2C. We don't find any limitation in the datasheet on the I2C. Is there any other document that could put constrain on the I2C like delays between commands and things like that.
Note: Before we had a timeout at 1ms and we were getting that error from time tot time. But since we have put the 10ms it become very reliable, but not perfect.