


Hello,
I used import tool tidl_model_import.out to generate the middle layers results .y file in tempDir folder,and using the same input data to generate the middle layers results .bin file on eve, and I found there is difference in some middle layers when compared two corresponding trace file.Here are the results:
trace_dump_1_320x320.y vs trace_dump_1_320x320.bin min: 128 max: 128 avg: 128.0
trace_dump_2_160x160.y vs trace_dump_2_160x160.bin min: 0 max: 0 avg: 0.0
trace_dump_3_160x160.y vs trace_dump_3_160x160.bin min: 0 max: 0 avg: 0.0
trace_dump_4_160x160.y vs trace_dump_4_160x160.bin min: 128 max: 128 avg: 128.0
trace_dump_5_160x160.y vs trace_dump_5_160x160.bin min: 0 max: 0 avg: 0.0
trace_dump_6_80x80.y vs trace_dump_6_80x80.bin min: 0 max: 0 avg: 0.0
trace_dump_7_80x80.y vs trace_dump_7_80x80.bin min: 128 max: 128 avg: 128.0
trace_dump_8_80x80.y vs trace_dump_8_80x80.bin min: 0 max: 0 avg: 0.0
trace_dump_9_80x80.y vs trace_dump_9_80x80.bin min: 0 max: 0 avg: 0.0
trace_dump_10_80x80.y vs trace_dump_10_80x80.bin min: 128 max: 128 avg: 128.0
trace_dump_11_80x80.y vs trace_dump_11_80x80.bin min: 128 max: 128 avg: 128.0
trace_dump_12_80x80.y vs trace_dump_12_80x80.bin min: 0 max: 0 avg: 0.0
trace_dump_13_40x40.y vs trace_dump_13_40x40.bin min: 0 max: 0 avg: 0.0
trace_dump_14_40x40.y vs trace_dump_14_40x40.bin min: 128 max: 128 avg: 128.0
trace_dump_15_40x40.y vs trace_dump_15_40x40.bin min: 0 max: 0 avg: 0.0
trace_dump_16_40x40.y vs trace_dump_16_40x40.bin min: 0 max: 0 avg: 0.0
trace_dump_17_40x40.y vs trace_dump_17_40x40.bin min: 128 max: 128 avg: 128.0
trace_dump_18_40x40.y vs trace_dump_18_40x40.bin min: 128 max: 128 avg: 128.0
trace_dump_19_40x40.y vs trace_dump_19_40x40.bin min: 0 max: 0 avg: 0.0
trace_dump_20_40x40.y vs trace_dump_20_40x40.bin min: 0 max: 0 avg: 0.0
trace_dump_21_40x40.y vs trace_dump_21_40x40.bin min: 128 max: 128 avg: 128.0
trace_dump_22_40x40.y vs trace_dump_22_40x40.bin min: 128 max: 128 avg: 128.0
trace_dump_23_40x40.y vs trace_dump_23_40x40.bin min: 0 max: 0 avg: 0.0
trace_dump_24_20x20.y vs trace_dump_24_20x20.bin min: 0 max: 0 avg: 0.0
trace_dump_25_20x20.y vs trace_dump_25_20x20.bin min: 128 max: 128 avg: 128.0
trace_dump_26_20x20.y vs trace_dump_26_20x20.bin min: 0 max: 0 avg: 0.0
trace_dump_27_20x20.y vs trace_dump_27_20x20.bin min: 0 max: 0 avg: 0.0
trace_dump_28_20x20.y vs trace_dump_28_20x20.bin min: 128 max: 128 avg: 128.0
trace_dump_29_20x20.y vs trace_dump_29_20x20.bin min: 128 max: 128 avg: 128.0
trace_dump_30_20x20.y vs trace_dump_30_20x20.bin min: 0 max: 0 avg: 0.0
trace_dump_31_20x20.y vs trace_dump_31_20x20.bin min: 0 max: 0 avg: 0.0
trace_dump_32_20x20.y vs trace_dump_32_20x20.bin min: 128 max: 128 avg: 128.0
trace_dump_33_20x20.y vs trace_dump_33_20x20.bin min: 128 max: 128 avg: 128.0
trace_dump_34_20x20.y vs trace_dump_34_20x20.bin min: 0 max: 0 avg: 0.0
trace_dump_35_20x20.y vs trace_dump_35_20x20.bin min: 0 max: 0 avg: 0.0
trace_dump_36_20x20.y vs trace_dump_36_20x20.bin min: 128 max: 128 avg: 128.0
trace_dump_37_20x20.y vs trace_dump_37_20x20.bin min: 128 max: 128 avg: 128.0
trace_dump_38_20x20.y vs trace_dump_38_20x20.bin min: 128 max: 128 avg: 128.0
trace_dump_39_20x20.y vs trace_dump_39_20x20.bin min: 128 max: 128 avg: 128.0
trace_dump_40_20x20.y vs trace_dump_40_20x20.bin min: 128 max: 128 avg: 128.0
trace_dump_41_20x20.y vs trace_dump_41_20x20.bin min: 128 max: 128 avg: 128.0
trace_dump_42_20x20.y vs trace_dump_42_20x20.bin min: 0 max: 0 avg: 0.0
trace_dump_43_40x40.y vs trace_dump_43_40x40.bin min: 128 max: 128 avg: 128.0
trace_dump_44_40x40.y vs trace_dump_44_40x40.bin min: 128 max: 128 avg: 128.0
trace_dump_45_40x40.y vs trace_dump_45_40x40.bin min: 128 max: 128 avg: 128.0
trace_dump_46_40x40.y vs trace_dump_46_40x40.bin min: 0 max: 0 avg: 0.0
trace_dump_47_40x40.y vs trace_dump_47_40x40.bin min: 0 max: 220 avg: 55.7348828125
trace_dump_48_80x80.y vs trace_dump_48_80x80.bin min: 84 max: 246 avg: 139.531689453125
trace_dump_49_80x80.y vs trace_dump_49_80x80.bin min: 123 max: 129 avg: 127.6588427734375
trace_dump_50_80x80.y vs trace_dump_50_80x80.bin min: 124 max: 130 avg: 127.7884716796875
trace_dump_51_80x80.y vs trace_dump_51_80x80.bin min: 0 max: 2 avg: 0.000390625
trace_dump_52_80x80.y vs trace_dump_52_80x80.bin min: 0 max: 1 avg: 1.220703125e-05
trace_dump_53_160x160.y vs trace_dump_53_160x160.bin min: 128 max: 129 avg: 128.00000061035155
trace_dump_54_160x160.y vs trace_dump_54_160x160.bin min: 128 max: 128 avg: 128.0
trace_dump_55_160x160.y vs trace_dump_55_160x160.bin min: 128 max: 128 avg: 128.0
trace_dump_56_160x160.y vs trace_dump_56_160x160.bin min: 0 max: 0 avg: 0.0
trace_dump_57_160x160.y vs trace_dump_57_160x160.bin min: 0 max: 0 avg: 0.0
trace_dump_58_320x320.y vs trace_dump_58_320x320.bin min: 128 max: 128 avg: 128.0
trace_dump_59_320x320.y vs trace_dump_59_320x320.bin min: 128 max: 128 avg: 128.0
trace_dump_60_320x320.y vs trace_dump_60_320x320.bin min: 128 max: 128 avg: 128.0
trace_dump_61_320x320.y vs trace_dump_61_320x320.bin min: 0 max: 0 avg: 0.0
trace_dump_62_320x320.y vs trace_dump_62_320x320.bin min: 128 max: 128 avg: 128.0
trace_dump_63_20x20.y vs trace_dump_63_20x20.bin min: 0 max: 214 avg: 78.5892578125
trace_dump_64_10x10.y vs trace_dump_64_10x10.bin min: 0 max: 206 avg: 32.630703125
trace_dump_65_10x10.y vs trace_dump_65_10x10.bin min: 0 max: 254 avg: 44.3418359375
trace_dump_66_10x10.y vs trace_dump_66_10x10.bin min: 18 max: 201 avg: 111.76666666666667
and we would find there is difference in some layers
trace_dump_47_40x40.y vs trace_dump_47_40x40.bin min: 0 max: 220 avg: 55.7348828125
trace_dump_48_80x80.y vs trace_dump_48_80x80.bin min: 84 max: 246 avg: 139.531689453125
trace_dump_49_80x80.y vs trace_dump_49_80x80.bin min: 123 max: 129 avg: 127.6588427734375
trace_dump_50_80x80.y vs trace_dump_50_80x80.bin min: 124 max: 130 avg: 127.7884716796875
trace_dump_51_80x80.y vs trace_dump_51_80x80.bin min: 0 max: 2 avg: 0.000390625
trace_dump_52_80x80.y vs trace_dump_52_80x80.bin min: 0 max: 1 avg: 1.220703125e-05
trace_dump_53_160x160.y vs trace_dump_53_160x160.bin min: 128 max: 129 avg: 128.00000061035155
trace_dump_63_20x20.y vs trace_dump_63_20x20.bin min: 0 max: 214 avg: 78.5892578125
trace_dump_64_10x10.y vs trace_dump_64_10x10.bin min: 0 max: 206 avg: 32.630703125
trace_dump_65_10x10.y vs trace_dump_65_10x10.bin min: 0 max: 254 avg: 44.3418359375
trace_dump_66_10x10.y vs trace_dump_66_10x10.bin min: 18 max: 201 avg: 111.76666666666667
and from the import tool debug information,we konw that:
47, TIDL_ConvolutionLayer , conv35
48, TIDL_Deconv2DLayer , conv_transpose2
49, TIDL_BatchNormLayer , batch_norm37
50, TIDL_BatchNormLayer , bn_scale37
51, TIDL_BatchNormLayer , relu24
52, TIDL_ConvolutionLayer , conv36
53, TIDL_Deconv2DLayer , conv_transpose3
54, TIDL_BatchNormLayer , batch_norm39
55, TIDL_BatchNormLayer , bn_scale39
56, TIDL_BatchNormLayer , relu26
57, TIDL_ConvolutionLayer , conv37
58, TIDL_Deconv2DLayer , conv_transpose_seg
59, TIDL_BatchNormLayer , batch_norm_seg
60, TIDL_BatchNormLayer , bn_scale_seg
61, TIDL_BatchNormLayer , relu_seg
62, TIDL_ConvolutionLayer , conv_seg
63, TIDL_ConvolutionLayer , conv40
64, TIDL_ConvolutionLayer , conv41
65, TIDL_ConvolutionLayer , conv42
66, TIDL_ConvolutionLayer , conv_pairs
and below is my part model that happen this:
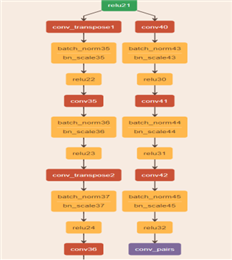
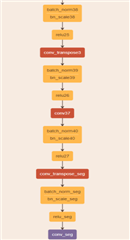
So Why does this happen?
Thanks,
chen poca
