Other Parts Discussed in Thread: TMDSEVM572X
Hello Champs,
HW: TMDSEVM572X
SW: Processor SDK Linux 06_03_00_106,
Machine Learning: TIDL caffe-jacinto。
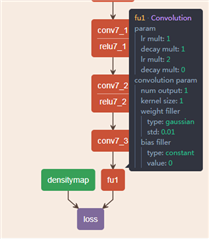
Customer used caffe-jacinto to train a network,define the last layer Convolution kernel as 1*1, output is 1. But when training, it prompted error message. 
There is similar structure in TI example except that the output is different
What's wong?
object detection.mobilenet,both conv3_1/sep and conv3_2/sep are kernel 1*1,group is 1,but the output channel doesn't match group.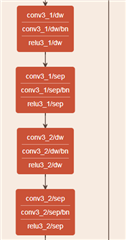
Customer's network configuration.
layer {
name: "fu1_1/dw"
type: "Convolution"
bottom: "conv7_3"
top: "fu1_1/dw"
convolution_param {
num_output: 64
bias_term: false
pad: 1
kernel_size: 3
group: 64
stride: 1
weight_filler {
type: "msra"
}
dilation: 1
}
}
layer {
name: "fu1_1/dw/bn"
type: "BatchNorm"
bottom: "fu1_1/dw"
top: "fu1_1/dw"
batch_norm_param {
scale_bias: true
}
}
layer {
name: "relu1_1/dw"
type: "ReLU"
bottom: "fu1_1/dw"
top: "fu1_1/dw"
}
layer {
name: "fu1_1/sep"
type: "Convolution"
bottom: "fu1_1/dw"
top: "fu1_1/sep"
convolution_param {
num_output: 64
bias_term: false
pad: 0
kernel_size: 1
group: 1
stride: 1
weight_filler {
type: "msra"
}
dilation: 1
}
}
layer {
name: "fu1_1/sep/bn"
type: "BatchNorm"
bottom: "fu1_1/sep"
top: "fu1_1/sep"
batch_norm_param {
scale_bias: true
}
}
layer {
name: "relu1_1/sep"
type: "ReLU"
bottom: "fu1_1/sep"
top: "fu1_1/sep"
}
layer {
name: "fu1_2/dw"
type: "Convolution"
bottom: "fu1_1/sep"
top: "fu1_2/dw"
convolution_param {
num_output: 64
bias_term: false
pad: 1
kernel_size: 3
group: 64
stride: 1
weight_filler {
type: "msra"
}
dilation: 1
}
}
layer {
name: "fu1_2/dw/bn"
type: "BatchNorm"
bottom: "fu1_2/dw"
top: "fu1_2/dw"
batch_norm_param {
scale_bias: true
}
}
layer {
name: "relu1_2/dw"
type: "ReLU"
bottom: "fu1_2/dw"
top: "fu1_2/dw"
}
layer {
name: "fu1_2/sep"
type: "Convolution"
bottom: "fu1_2/dw"
top: "estdmap"
convolution_param {
num_output: 1
bias_term: false
pad: 0
kernel_size: 1
group: 1
stride: 1
weight_filler {
type: "msra"
}
dilation: 1
}
}
Customer's network structure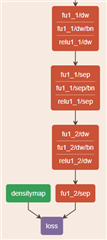
Thanks.
Rgds
Shine