


HI,
I'm trying to use ti-processor-sdk-rtos-j7200-evm-08_00_00_12 with CCS 10.4 on the J721EXCP01EVM board.
I have successfully built a uart_test program (@ pdk_j7200_08_00_00_37\packages\ti\csl\example\uart\uart_test) for mpu1_0.
In debugging on CCS 10.4, I found ESR_EL3 on mpu1_0 indicated an error value just after loading the program above as shown in the attached figure below.
(I followed [1] for CCS setup)
[1] software-dl.ti.com/.../ccs_setup_j7200.html
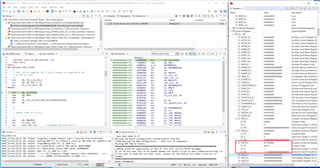
I guess that this error is derived from a GEL file. Does a release version binary booted from SBL have the same problem too?
Other proprietary (my own) programs for mpu1_0 and mpu1_1 which run with AArch64/EL1 receive an unexpected synchronous exception with ESR_EL1 = 0x02000000 after 30min or 1hour execution. This error is classified into "unknown reason" at [2].
[2] developer.arm.com/.../ESR-EL1--Exception-Syndrome-Register--EL1-
ESR_EL1 0x02000000 Exception Syndrome Register (EL1) [Core]
EC 000000 Exception Class
IL 1 Instruction Length (1=32 bits)
ISS 0000000000000000000000000 Instruction Specific Syndrome
I investigated the root cause for that, but I cannot find it yet. The program seemed to operate without any problem because code, stacks and CPU registers seemed correct when a target cpu core received the synchronous exception.
Even in this scenario, the ESR_EL3 value of both mpu1_0 and mpu1_1 just after loading each program binary was 0x62383011. However, the ESR_EL3 value became 0x1FE00000 (as shown in the attached figure) just after 1-step over execution on CCS.
ESR_EL3 0x62383011 Exception Syndrome Register (EL3) [Core]
EC 011000 Exception Class
IL 1 Instruction Length (1=32 bits)
ISS 0001110000011000000010001 Instruction Specific Syndrome
So, I'm now suspecting that A72 cores become invisibly unstable due to wrong initialization by a GEL file (or SBL), then they are capable of causing other errors.
Many thanks,



