Hi All,
We are having an issue with a core stall / hang / lock up, with a custom board.
While we are operating in a single core configuration, we do not believe this issue is related to Errata #798870 as we:
- have the Hazard Detect timeout bit set in L2ACTLR
- have a periodic DMA running as per the workaround (which continues to operate after stall)
- have observed the stall even with the L2 Cache disabled (C-bit in SCTLR clear)
- can regularly experience the stall within a couple of minutes
We have confirmed that the peripherals we are accessing (DDR3, PCIe) still respond by accessing them over DAP.
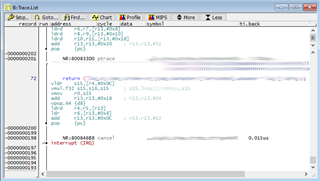
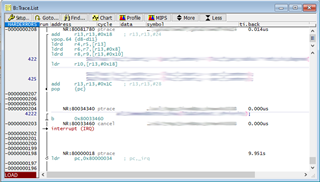
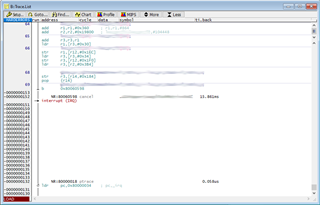
We currently use a Lauterbach probe; recently we had a similar stalling issue which was alleviated by changing the commands used to connect the probe. For our probe, using "System.up" to initially connect caused a version of our application to stall in the same section every time (i.e. we connect with "system.up", load the bootloader, run the bootloader, load the image, run the image, then it stalled in roughly the same area each time). To fix this we found that using "system.attach" followed by a "break.direct", or running the application without the debugger connected (physically or otherwise) did not result in a stall.
The both commands initialise the debug/jtag port; the difference is that attach does not perform a reset, and does not stop the change the processor state.
Unfortunately, disconnecting the debugger physically still results in our current stall situation. We do not know if this is a separate stall issue, or if the debugger was exacerbating the same stall issue.
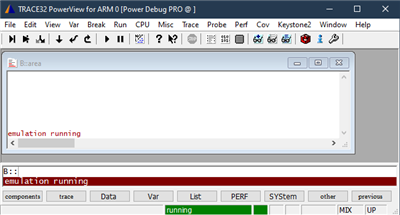
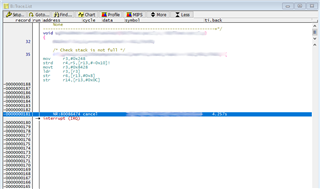
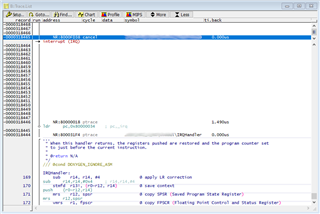
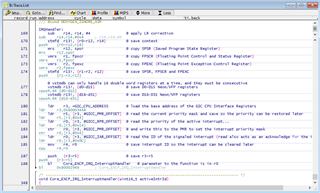
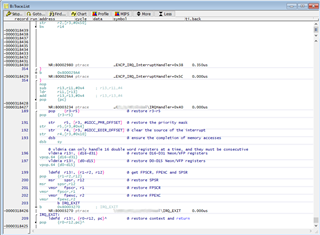
We would like to be able to interrogate the core and check what state it is in but, due to the stall, all access to and control over the core via the debugger ceases. For example, trying to halt execution results in the debugger throwing an "Emulation running" error; and trying to access core registers results in failure and "bus error"s.
Are there any steps we can take to try to work out what is happening and why? Are there any registers we can/should interrogate to see the internal status of the SoC?
Many thanks