

Other Parts Discussed in Thread: AM3357, , AM6442
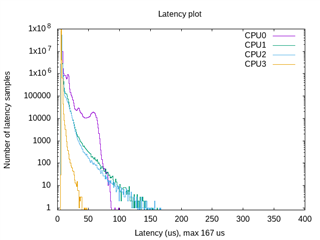
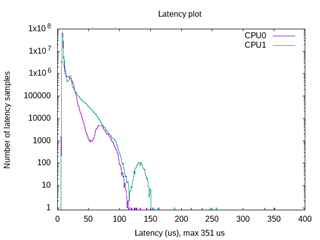
How can I measure interrupt latency on Sitara multicore devices such as AM625 and compare the results to single core devices such as AM3357?
.
For more information on testing interrupt latency with cyclictest, reference e2e.ti.com/.../faq-linux-how-do-i-test-the-real-time-performance-of-an-am3x-am4x-am6x-soc