Other Parts Discussed in Thread: AMC7812
if(cs == 0) {
spiRegs->SPIDELAY = (8 << CSL_SPI_SPIDELAY_C2TDELAY_SHIFT) |
(8 << CSL_SPI_SPIDELAY_T2CDELAY_SHIFT); //(8+1)*6ns=54ns
/* default chip select register */
spiRegs->SPIDEF = CSL_SPI_SPIDEF_RESETVAL; //T2C END TO CHIP SELECT ; C2T CHIP SELECET TO START
} else if(cs == 1) {
spiRegs->SPIDELAY = (6 << CSL_SPI_SPIDELAY_C2TDELAY_SHIFT) | //7*6ns=42ns 4*6ns=24ns
(3 << CSL_SPI_SPIDELAY_T2CDELAY_SHIFT);
}
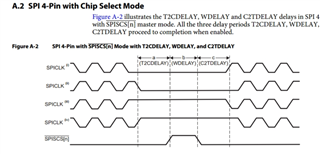
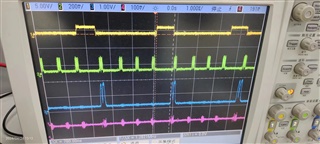
The delay of C2T and T2C can be understood as chip selection time and chip selection hold time, resulting in clock after time or clock end time delay.
But my concern is why the WDELAY time in the timing chart is so large, as shown in the picture at 780ns.
In the DEMO program, SPI_SPIFMT.WDELAY does not have a time set, and the default value of the register is 0. And with the default value of 0 for SPI_SPIDAT_1 WDEL, why does the CS switching time for each frame of data take 780ns?
Now the core board circuit is fully encapsulated, not open to the public, and cannot be rectified. We directly introduce SPI data cables from the core board circuit for timing testing. Now I want to know why the hardware circuit is not executed according to the software settings?
Our project now requires an interruption time of 3.3us to complete multiple SPI controls, and this delay in project design cannot be accepted
In the DEMO program, SPI_SPIFMT.WDELAY does not have a time set, and the default value of the register is 0. And with the default value of 0 for SPI_SPIDAT_1 WDEL, why does the CS switching time for each frame of data take 780ns?
Now the core board circuit is fully encapsulated, not open to the public, and cannot be rectified. We directly introduce SPI data cables from the core board circuit for timing testing. Now I want to know why the hardware circuit is not executed according to the software settings?
Our project now requires an interruption time of 3.3us to complete multiple SPI controls, and this delay in project design cannot be accepted
Suspect that there is a delay when the CPU accesses the external device. Every time the transmission is retransmitted, there is a certain delay between the CPU and the external device. Is it due to internal limitations of the CPU.