Other Parts Discussed in Thread: MATHLIB
Tool/software: TI C/C++ Compiler
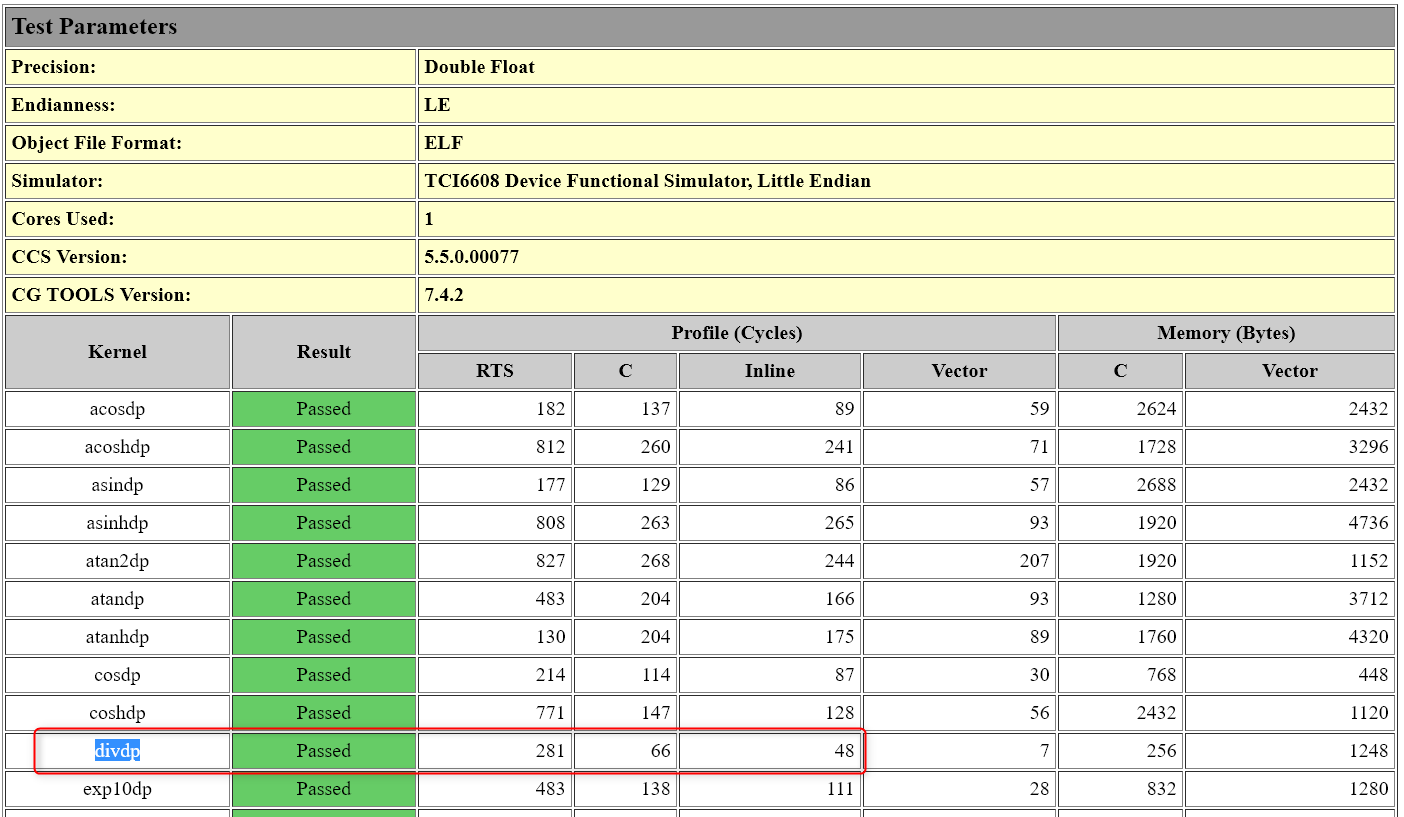
Currently I am stuck at slow DSP calculating double division, which costs me almost 250 cycles(with O3 option and memory cache) for one double type division operation. In the datasheet of TCI6614, it has below description:
The C66x core incorporates 90 new instructions targeted for floating point (FPi) and vector math oriented (VPi) processing....The C66x CPU also
supports SIMD for floating-point operations.
This show several instruction enhancement of C66x. I am wondering if any special compiler option can switch on these enhancements to speed up my float-point division calculation? Or any suggestion to speed up the double type division will be appreciated.