Other Parts Discussed in Thread: 66AK2G12, CC3135,
Hello, a customer is seeing a concerning issue under a specific set of circumstances that seems to be related to some interaction between the UART and the MQTT client that has us baffled at this point.
Background: The customer is using a TI 66AK2G12 SoC running TiRTOS as the OS and writing data to the UART to be published via MQTT. They are sending out two MQTT messages per second with a total payload of ~100 and 800 bytes at QoS 1. We have not made any modifications to SDK MQTT libraries. This has been observed using both SDKs 3.20 and 5.30 and their related service packs.
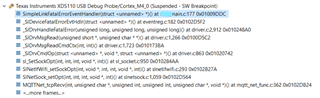
Issue: After some time (seems to range between 15-60 minutes and occur somewhat faster using SDK 5.30) we suffer an MQTT disconnection and are unable to reconnect to the broker without undergoing a reset. At this time the HTTP servers also are unresponsive, however the AP reports we are still connected. We are unable to reproduce this issue when another host is used to write the messages via UART as well as when the published messages are hardcoded, including if we drastically up the frequency and/or size of the published messages. Equally as perplexing is that if the customer switches from using TiRTOS to using a Linux version for the OS, they report they are unable to observe the issue. We were finally able to observe a debug session of what's occurring when this event happens, and at the time where the MQTT disconnection occurs, there is a SL_DEVICE_EVENT_FATAL_SYNC_LOSS. This is the call stack:

Both devices are utilizing RTS/CTS flow control, and the customer reports that the baud rate does not seem to affect the issue. They have reported other issues related to the TiRTOS UART driver in the past, but have (seemingly) resolved these issues. Interestingly, if a 10ms delay (have not tested with less, but I suspect that number may be able to be lowered) is inserted between the UART writes in their code the issue seems to be resolved. Similarly, if a 0.10ms delay is inserted prior to calling MQTTClient_publish the issue is likewise resolved. The same issues are observed when QoS 2 is used, but not with QoS 0. I am unsure of how the UART is interacting with the MQTT to cause the fatal event and why they are only observing this when using TiRTOS.
Questions: Have any similar issues been observed before? Why would the issue not occur when the host's OS is changed? Why does inserting a delay between UART writes or before a call to MQTTClient_publish resolve the issue--i.e., what is the overlap? Where should we be looking to solve this?
Thanks for your help.