Part Number: TMDS243EVM
Other Parts Discussed in Thread: SYSCONFIG
Tool/software:
Hi Ti Expert,
(FPGA kit): https://www.arrow.com/en/products/dk-dev-10cx220-a/intel?q=DK-DEV-10CX220-A
I try to use this FPGA kit as EP and 234EVM as RC.
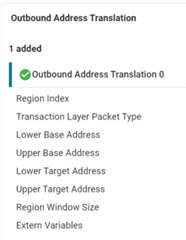
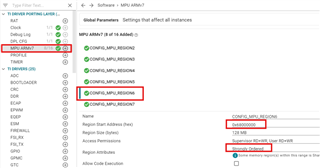
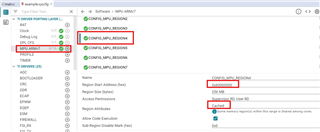
The EP has two bar, bar0 and bar1.
I can read the statue_cmd from EP, but can't configure bar for EP. The following are the code of mine.
It always stuck in : type0BarIdx.idx reading in Pcie_cfgBar().
My SDK version:mcu_plus_sdk_am243x_09_00_00_35
Pleas help me with that!
Thanks
Chunyang
int32_t pcie_fpga_ep_test(Pcie_Handle handle)
{
int32_t status = SystemP_SUCCESS;
Pcie_Registers getRegs;
Pcie_StatusCmdReg statusCmd;
memset (&getRegs, 0, sizeof(getRegs));
getRegs.statusCmd = &statusCmd;
status = Pcie_readRegs (handle, PCIE_LOCATION_REMOTE, &getRegs);
if (SystemP_SUCCESS != status)
{
DebugP_log("FPGA state read test fail\r\n");
}
else
{
DebugP_log("FPGA state read test done\r\n");
}
return status;
}
int32_t pcie_fpga_ep_bar1_cfg(Pcie_Handle handle)
{
int32_t status = SystemP_SUCCESS;
Pcie_BarCfg barCfg;
barCfg.location = PCIE_LOCATION_REMOTE;
barCfg.mode = PCIE_EP_MODE;
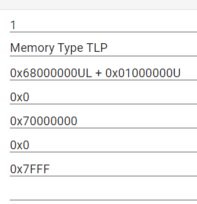
barCfg.base = 0x70000000;
barCfg.prefetch = PCIE_BAR_NON_PREF;
barCfg.type = PCIE_BAR_TYPE32;
barCfg.memSpace = PCIE_BAR_MEM_MEM;
barCfg.idx = 0;//1;
status = Pcie_cfgBar (handle, &barCfg);
//DebugP_assert(SystemP_SUCCESS == status);
if (SystemP_SUCCESS != status)
{
DebugP_log("FPGA Bar1 configure fail\r\n");
}
else
{
DebugP_log("FPGA Bar1 configure done\r\n");
}
return status;
}