


Other Parts Discussed in Thread: AM3359
Hello,
Our AM3359 is not performing as fast as we had hoped when accessing certain module registers.
As an example, we are toggling an GPIO pin as fast as possible in u-boot.
An objdump of the code reads:
...
*((volatile u32*)0x481ac190) = 0x8000; 80128324: e5823190 str r3, [r2, #400] *((volatile u32*)0x481ac194) = 0x8000; 80128328: e5823194 str r3, [r2, #404] *((volatile u32*)0x481ac190) = 0x8000; 8012832c: e5823190 str r3, [r2, #400] *((volatile u32*)0x481ac194) = 0x8000; 80128330: e5823194 str r3, [r2, #404] *((volatile u32*)0x481ac190) = 0x8000; 80128334: e5823190 str r3, [r2, #400] *((volatile u32*)0x481ac194) = 0x8000; 80128338: e5823194 str r3, [r2, #404]
...
Using an oscilloscope, we measure the time between each instruction to 220ns as seen below.
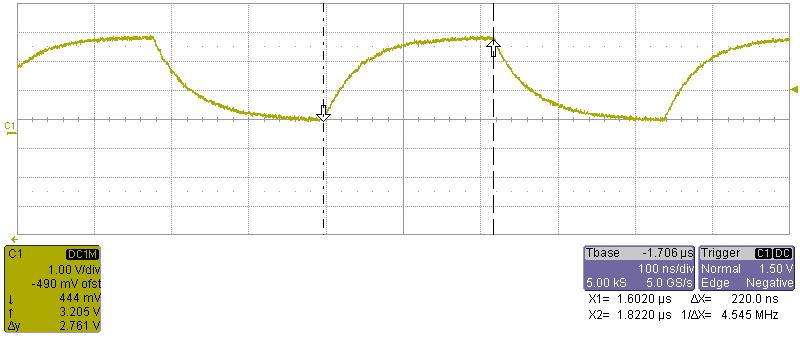
We are having the same problem when accessing the GPMC and the DMTimer modules.
Does anyone have a clue about what we might have configured wrong?
Thanks in advance,
Rickard

