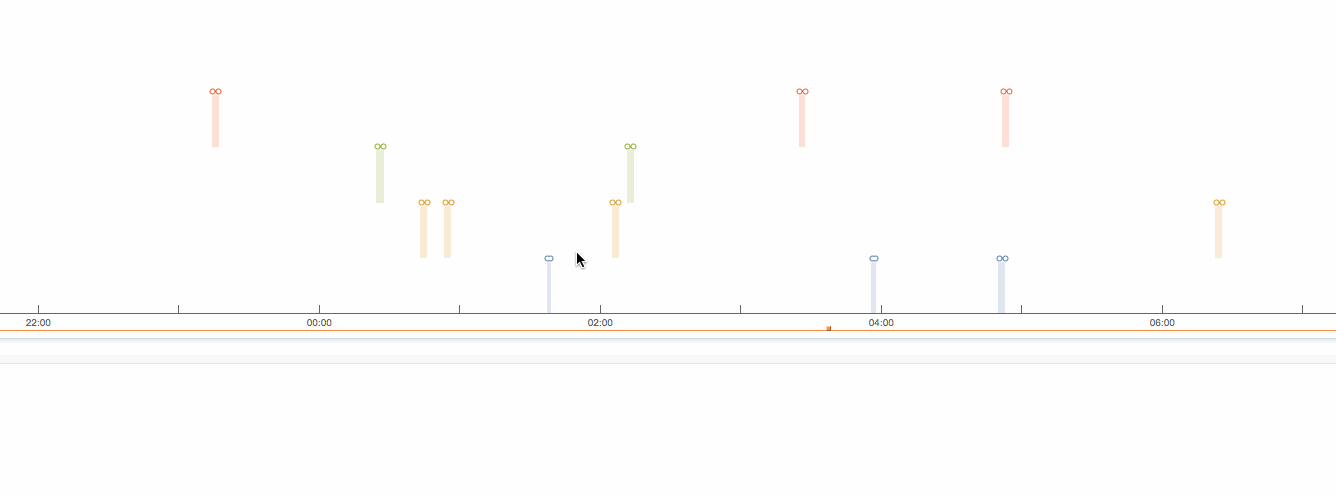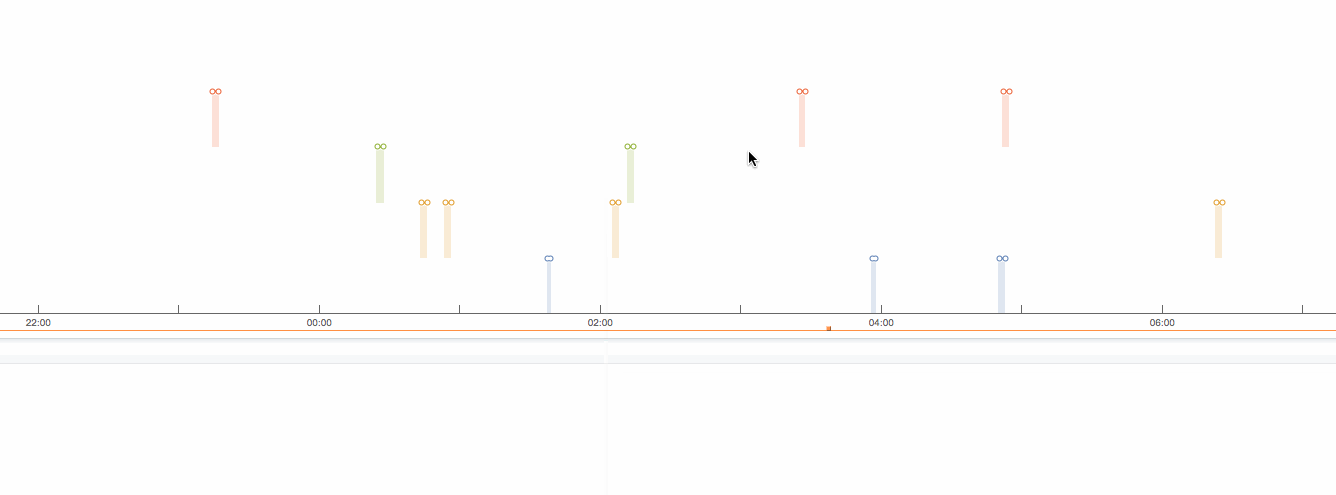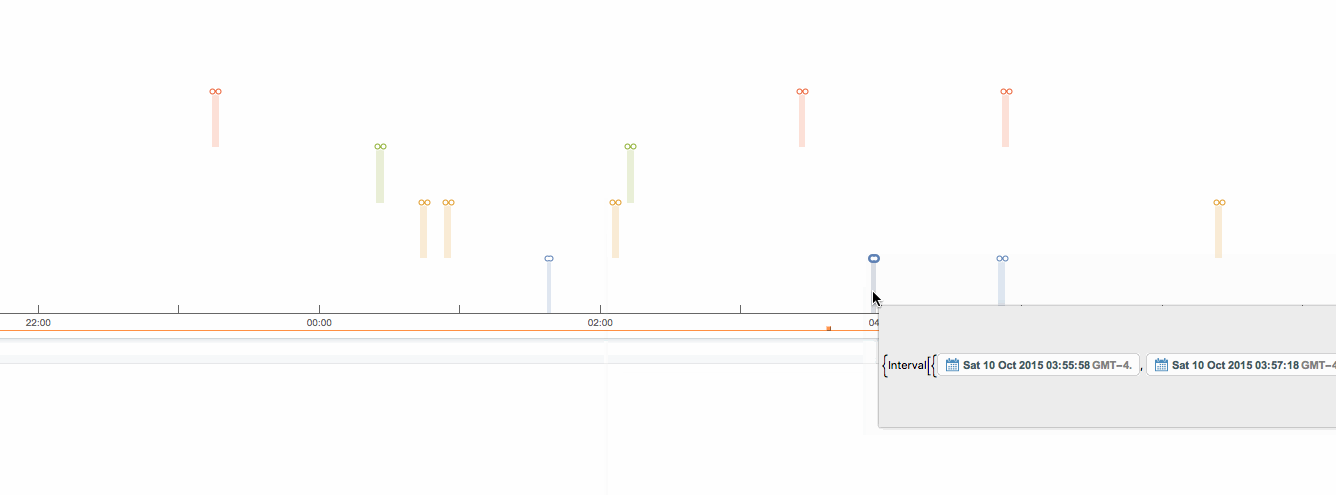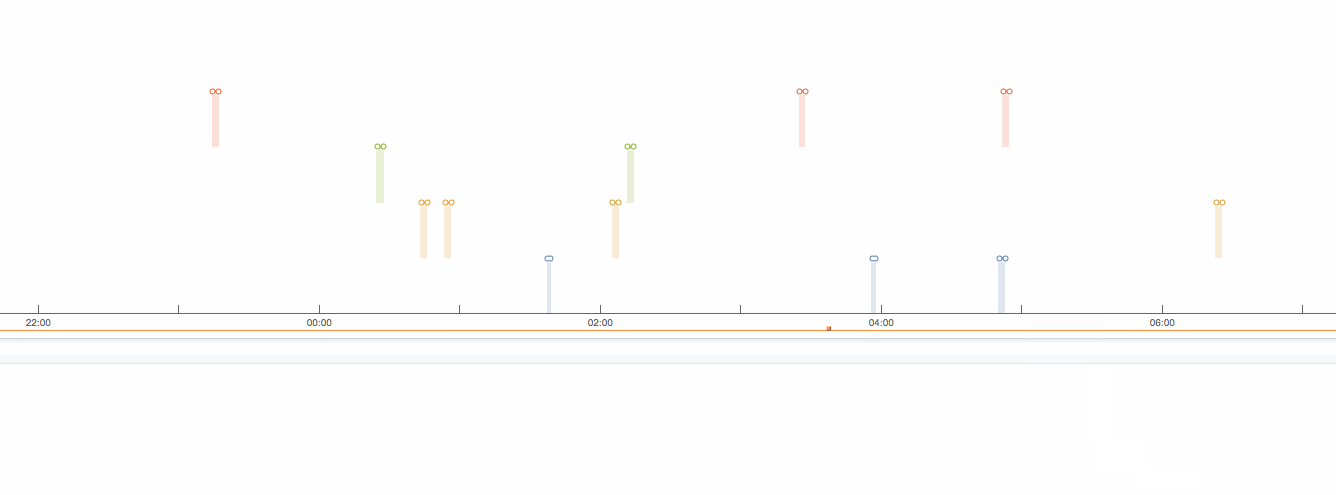
I am working on a board which uses a SOM with an AM3354. There is a LCD touchscreen which is used with a QT app, there is no X server. I am seeing a behavior where apparently randomly, the LCD screen gets totally garbled and goes through a series of apparently random data being displayed.
After a few minutes of going through this, the system recovers and continues to function normally. Whenever this happens, I see a lot of SGX messages being dumped to the kernel log:
[ 2624.874797] PVR_K: User requested SGX debug info
[ 2624.879696] PVR_K: SGX debug (SGX_DDK_Linux_CustomerTI sgxddk 1.10@2359475)
[ 2624.887071] PVR_K: Flip Command Complete Data 0 for display device 11:
[ 2624.893958] PVR_K: SRC 0: ROC DevVAddr:0xD8010DC ROP:0x53df ROC:0x53dc, WOC DevVAddr:0xD8010CC WOP:0x29f0 WOC:0x29ef
[ 2624.905153] PVR_K: SRC 1: ROC DevVAddr:0xD8010B4 ROP:0x53de ROC:0x53db, WOC DevVAddr:0xD8010A4 WOP:0x29ef WOC:0x29ee
[ 2624.916345] PVR_K: Host Ctl flags= 00000006
[ 2624.920840] PVR_K: SGX Host control:
[ 2624.924609] PVR_K: (HC-0) 0x00000001 0x00000000 0x00000000 0x00000001
[ 2624.931502] PVR_K: (HC-10) 0x00000000 0x00000000 0x0000000A 0x00030D40
[ 2624.938485] PVR_K: (HC-20) 0x00000000 0x00000004 0x00000000 0x00000000
[ 2624.945468] PVR_K: (HC-30) 0x00000000 0x00279E4B 0xEFD0A0E0 0x00000000
[ 2624.952437] PVR_K: (HC-40) 0x00000000 0x00000000 0x0006131B 0x00000000
[ 2624.959412] PVR_K: SGX TA/3D control:
[ 2624.963273] PVR_K: (T3C-0) 0x0F003000 0x0F003120 0x0F002000 0x00000000
[ 2624.970253] PVR_K: (T3C-10) 0x00000000 0x00000000 0x00000002 0x00000000
[ 2624.977325] PVR_K: (T3C-20) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2624.984386] PVR_K: (T3C-30) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2624.991457] PVR_K: (T3C-40) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2624.998528] PVR_K: (T3C-50) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2625.005601] PVR_K: (T3C-60) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2625.012661] PVR_K: (T3C-70) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2625.019734] PVR_K: (T3C-80) 0x00000000 0x00000000 0x0F0AD518 0x0F000000
[ 2625.026809] PVR_K: (T3C-90) 0x9C2F3000 0x0F095DC0 0x00000000 0x0F08B920
[ 2625.033870] PVR_K: (T3C-A0) 0x0F00AEA0 0x0F0AD55C 0x0F08B920 0x00000000
[ 2625.040941] PVR_K: (T3C-B0) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2625.048015] PVR_K: (T3C-C0) 0x00000000 0x00000000 0x000053DD 0x000053DC
[ 2625.055092] PVR_K: (T3C-D0) 0x0F000000 0x8000B000 0x8004B000 0x0F004000
[ 2625.062153] PVR_K: (T3C-E0) 0x0F00A420 0x0F00A740 0x0F08B000 0x0F08B000
[ 2625.069228] PVR_K: (T3C-F0) 0x00000000 0x000001FD 0x000001FD 0x00000000
[ 2625.076302] PVR_K: (T3C-100) 0x00000003 0x00000000 0x00000000 0x00000001
[ 2625.083454] PVR_K: (T3C-110) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2625.090613] PVR_K: SGX Kernel CCB WO:0x94 RO:0x94
[ 2683.954773] PVR_K: User requested SGX debug info
[ 2683.959687] PVR_K: SGX debug (SGX_DDK_Linux_CustomerTI sgxddk 1.10@2359475)
[ 2683.967052] PVR_K: Flip Command Complete Data 0 for display device 11:
[ 2683.973942] PVR_K: SRC 0: ROC DevVAddr:0xD8010DC ROP:0x53f3 ROC:0x53f0, WOC DevVAddr:0xD8010CC WOP:0x29fa WOC:0x29f9
[ 2683.985141] PVR_K: SRC 1: ROC DevVAddr:0xD8010B4 ROP:0x53f2 ROC:0x53ef, WOC DevVAddr:0xD8010A4 WOP:0x29fa WOC:0x29f8
[ 2683.996339] PVR_K: Host Ctl flags= 00000006
[ 2684.000836] PVR_K: SGX Host control:
[ 2684.004606] PVR_K: (HC-0) 0x00000001 0x00000000 0x00000000 0x00000001
[ 2684.011501] PVR_K: (HC-10) 0x00000000 0x00000000 0x0000000A 0x00030D40
[ 2684.018484] PVR_K: (HC-20) 0x00000000 0x00000004 0x00000000 0x00000000
[ 2684.025468] PVR_K: (HC-30) 0x00000000 0x00288513 0xEFD0A0E0 0x00000000
[ 2684.032439] PVR_K: (HC-40) 0x00000000 0x00000000 0x000614E1 0x00000000
[ 2684.039416] PVR_K: SGX TA/3D control:
[ 2684.043278] PVR_K: (T3C-0) 0x0F003000 0x0F003120 0x0F002000 0x00000000
[ 2684.050264] PVR_K: (T3C-10) 0x00000000 0x00000000 0x00000002 0x00000000
[ 2684.057340] PVR_K: (T3C-20) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2684.064402] PVR_K: (T3C-30) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2684.071479] PVR_K: (T3C-40) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2684.078555] PVR_K: (T3C-50) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2684.085629] PVR_K: (T3C-60) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2684.092690] PVR_K: (T3C-70) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2684.099765] PVR_K: (T3C-80) 0x00000000 0x00000000 0x0F0AD55C 0x0F000000
[ 2684.106841] PVR_K: (T3C-90) 0x9C2F3000 0x0F094A00 0x00000000 0x0F08B4C0
[ 2684.113902] PVR_K: (T3C-A0) 0x0F00AEA0 0x0F0AD55C 0x0F08B920 0x00000000
[ 2684.120977] PVR_K: (T3C-B0) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2684.128053] PVR_K: (T3C-C0) 0x00000000 0x00000000 0x000053F2 0x000053F0
[ 2684.135130] PVR_K: (T3C-D0) 0x0F000000 0x8000B000 0x8004B000 0x0F004000
[ 2684.142193] PVR_K: (T3C-E0) 0x0F00A420 0x0F00A740 0x0F08B000 0x0F08B000
[ 2684.149268] PVR_K: (T3C-F0) 0x00000000 0x000001FD 0x000001FD 0x00000000
[ 2684.156342] PVR_K: (T3C-100) 0x00000003 0x00000000 0x00000000 0x00000000
[ 2684.163496] PVR_K: (T3C-110) 0x00000000 0x00000000 0x00000000 0x00000000
[ 2684.170658] PVR_K: SGX Kernel CCB WO:0x3B RO:0x3B
I have tried to reproduce this behavior exhaustively but I simply cannot reproduce it at will. It seems to be completely non-deterministic. I would like to understand those messages that are spit out by the kernel, as may be that will help me debug this.
Thank you.