Hello
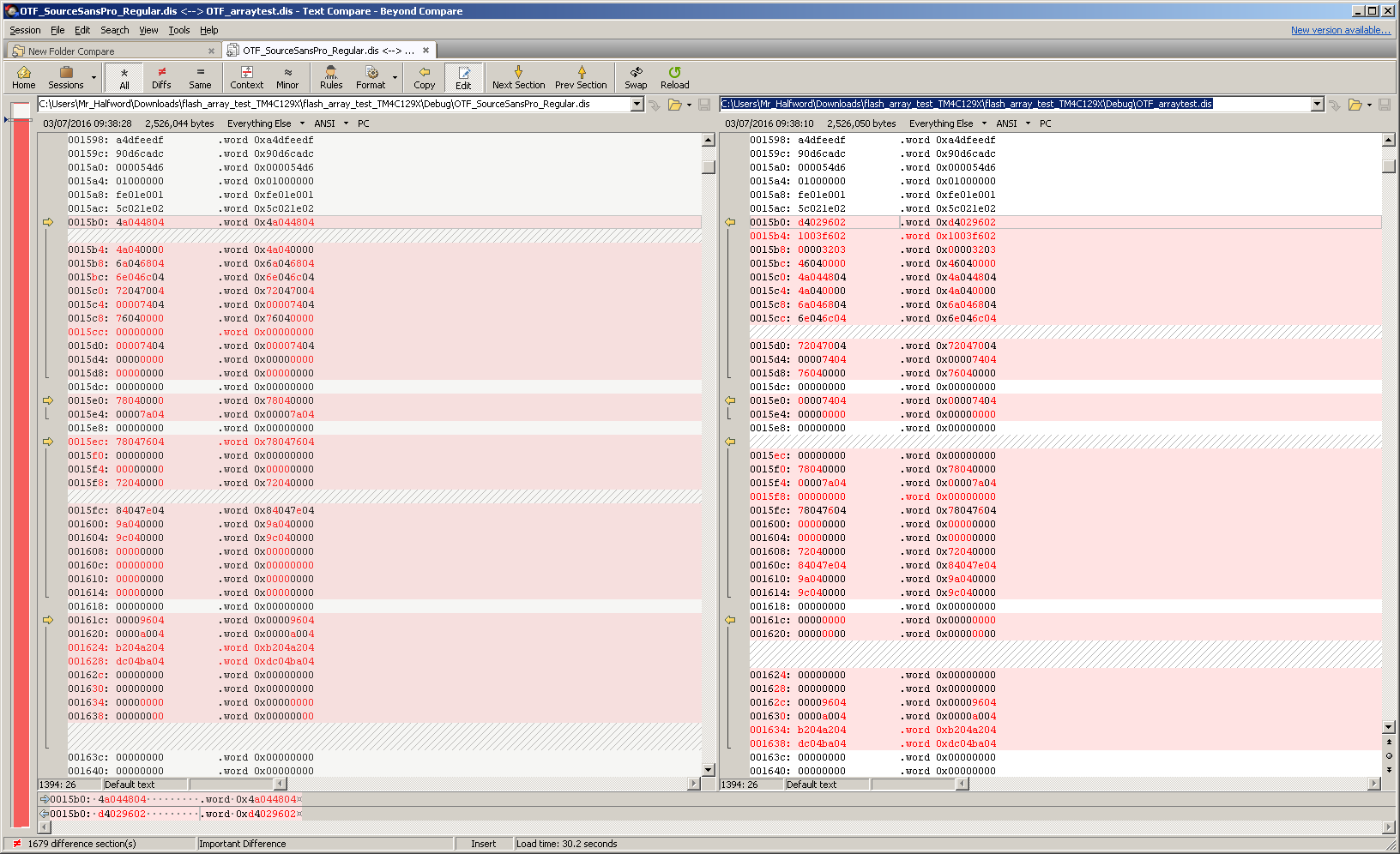
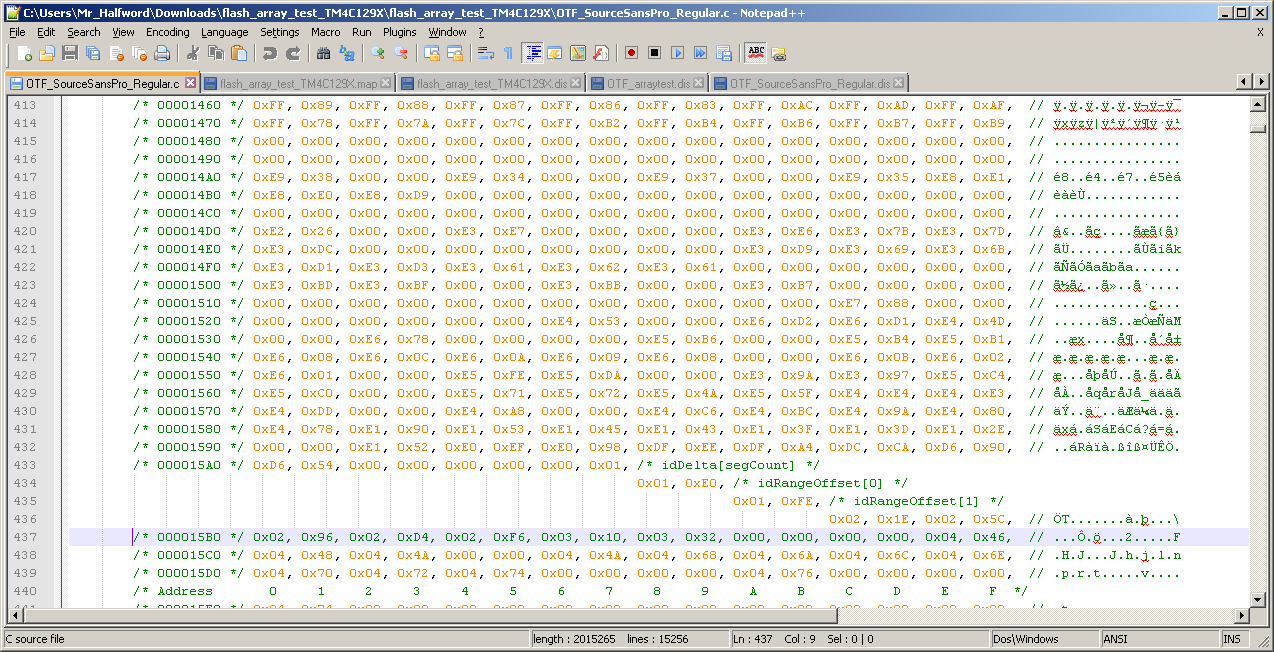
I'm trying to flash a huge array (280kB) to my TM4C129X (it's a font file) and I do array operations on it to parse the file and get its goodies and I've noticed that the array isn't loading properly into the chip's flash at least as far as the JTAG and program on board see it. I've verified that this exact code works on my RM48L952 (big difference in processor, I know) but when I read the flash out from the TM4C it ends up misaligned. The data at offset address 0x4454 in is 16B ahead of where it should be and by the time you get to the final address, offset 0x0003 95CF, the data stopped 0x190 before it should have.
I'm wondering if there's some difference in how the TM4C compiles large data arrays? I converted both outputs to binary and compared them; the TM4C binary output at the end of the file is not what it should be and is in fact compressed 0x190 bytes shorter than what it should be whereas the RM48's compiler made the array the exact bit for bit duplicate of what it should be.
Anyone have any ideas?
For reference:
RM48L952: Compiled with TI v5.1.14 on CCS 5.5
TM4C129: Compiled with TI v15.12.2.LTC on CCS 6.1.3
I realize that seems like a huge difference between the two compilers and environments, but the RM48 is kept on CCS5 for legacy reasons; compiling with the TI v5.2.5 leads to the same issue for the TM4C. The source files are identical.
Chris