


Part Number: TMS320F28384D
Other Parts Discussed in Thread: C2000WARE
Hello,
I have a question regarding the flash_kernel example inside the C2000 Ware 04.00.00.00 package. I am looking at the part of the code, which receives from UART data to be written to CPU1 flash, specifically at the function 'copyData()'. Please look at the below code marked in the rectangle.
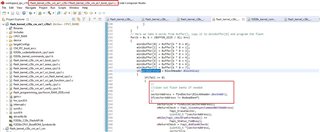
I am thinking about a scenario, where we may write flash data across the flash sector borders like e.g. 4 words to S0 and 4 words to S1.
The above code will cause problems in case that the variable 'BlockHeader.DestAddr' holds a value, which is not an integer multiple of 8.
Example:
Let us assume that the variable 'BlockHeader.DestAddr' holds a value of 0x81FFF (which is the last address of CPU1 Flash sector 0). In that case we would write one word inside Sector 0 and seven words inside Sector 1 without erasing Sector 1 before.
I don't know if that situation can occur (how the linker places code inside memory), but maybe the flash erase must be done again based on this if-condition:
sectorAddress = findSector(BlockHeader.DestAddr+7); // +7 since the 'miniBuffer[]' array is of size 8
if(sectorAddress != 0xdeadbeef)
{
...
What do you think, is the above scenario valid?
Another question would be also, if the API function 'Fapi_issueProgrammingCommand' (writing to flash) is able to detect if a user wants to program data across flash sector borders and handles this scenario correctly.
Thanks,
Inno

