Part Number: TMS320F28388D
Other Parts Discussed in Thread: TMDSCNCD28388D, C2000WARE
Hello
I wrote a function called HandleCmToCpu1IpcRequests inside my CPU1 project, which copies data from the CM->CPU1 message RAM into a structure in the following way:
memcpy(&s_CanTelegramReceivedFromMaster, (const void *)ipcAddr, (size_t)sizeof(s_CanTelegramReceivedFromMaster)
In the near future I have to run the function HandleCmToCpu1IpcRequests and all other functions, which are called out of that function, from RAM. This is required, since HandleCmToCpu1IpcRequests may be called out of an IRQ while the flash of the CPU1 might be in a process of erasing a sector. Therefore, I tried first to move the memcpy function itself to RAM via the linker command file, e.g. for the .TI.ramfunc section:
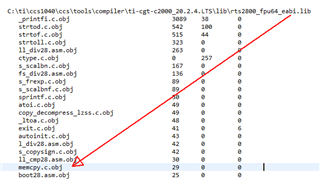
--library=rts2800_fpu64_eabi.lib<memcpy.c.obj>(.text)
But this is obviously not a good idea, since I received a linker warning and the firmware didn't work anymore:
"../2838x_FLASH_lnk_cpu1.cmd", line 92: warning #10068-D: no matching section
warning #10278-D: LOAD placement specified for section ".text:rts2800_fpu64_eabi.lib<memcpy.c.obj>". This section contains decompression routines required for linker generated copy tables and C/C++ auto-initialization. Must ensure that this section is copied to run address before the C/C++ boot code is executed or is placed with single allocation specifier (ex. "> MEMORY").
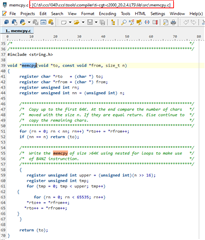
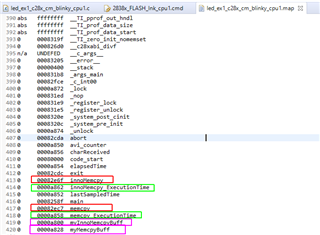
Afterwards, I copied the memcpy function from C:\ti\ccs1040\ccs\tools\compiler\ti-cgt-c2000_20.2.4.LTS\lib\src\memcpy.c to my project, renamed that function into innoMemcpy and moved it to the RAM:
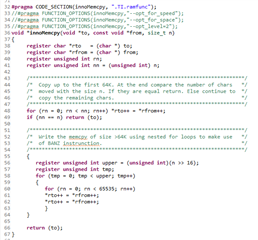
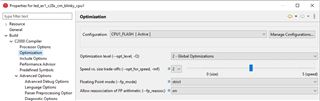
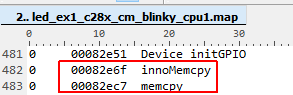
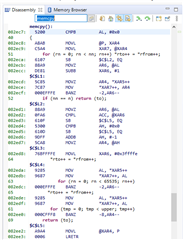
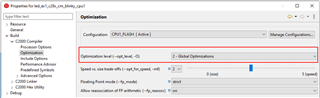
I measured now the execution time of the HandleCmToCpu1IpcRequests function via CPU timer 1. No matter which additional pragma I am using for innoMemcpy, like --opt_for_speed or opt_level=2 (see above picture), the innoMemcpy function is always twice a s slow as the memcpy of the rts2800_fpu64_eabi.lib library. So in the following picture, the first line is always faster than the second line by factor 2.
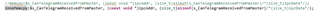
Is there any idea what could cause the difference in the execution time? How can I make the function innoMemcpy become as fast as memcpy?
Thanks,
Inno