Part Number: TMS320F28379D
Hello,
I'm looking at how I might best recover from a CANbus error situation.
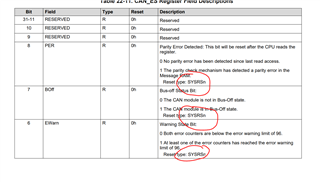
I currently have two f2837xD devices communicating over CANbus and under certain failure modes, the two devices end up trying to send and receive CAN messages with the same idents, this inevitably causes CAN bus errors and one of the devices locks up when the error counter exceeds the threshold. I can detect this once the errors exceed the threshold and create an interrupt, but by then from looking at the manual it seems I need to perform a CPU reset to recover the situation and clear the flags, which is a bit drastic. Below is how we trap errors currently:
if(statusB == CAN_INT_INT0ID_STATUS) //an interrupt is pending
{
status_inner = CANStatusGet(CANB_BASE, CAN_STS_CONTROL);
if(((status_inner & ~(CAN_ES_RXOK)) != 7) &&
((status_inner & ~(CAN_ES_RXOK)) != 0))
{
errorFlag = 1;
}

i.e by the time errorFlag goes to 1 it is too late to do anything about it and the CANport is locked up.
I think this code snippet was based on code a colleague of mine was given or shown by the TI team some time ago.
I can't see an easy way to detect the bus errors arising and say clear the error register whilst taking action to stop the channel from transmitting (that counter also needs a CPU reset it seems).
Are there any examples or suggestions for handling CANbus errors and being able to halt the bus before retrying and/or resetting the CAN port without having to reset the whole CPU?
regards
Steve