Part Number: TMS320F280039C
Hi folks. I have a question regarding to the CAN message data, more specifically, how the 8-byte message data gets interpreted into different types.
I am using standard CAN message, which has 8 bytes for the data field.
I defined the rxMsgBuf as follows:
union RxMsgBuf {
uint16_t rxMsgDataInt[4];
unsigned char rxMsgData[8];
uint64_t rxWhole;
}rxMsgBuf;
Using union here for myself to better understand how the data bytes being accessed. My understanding is, this union takes 8 bytes in total, and can be interpreted as
-- 4 16bit-integers (uint16_t rxMsgDataInt[4]), or
-- 8 1-byte character (unsigned char rxMsgData[8), or
-- a long 64-bit long int (uint64_t rxWhole), depending on how my application treats the data sent.
The message received will be transferred into this rxMsgBuf in interrupt, by
CAN_readMessage(CANA_BASE, MSG_OBJ_ID_RECEIVE, &rxMsgBuf);
And after that I set up the CAN receive object, and sent standard format data from external (a linux host), e.g. cansend 156#01.AF.00.20.00.00.00.F2.
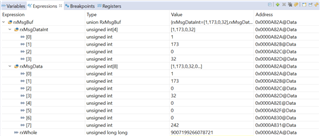
By watching the varible of the rxMsgBuf, here's what I got
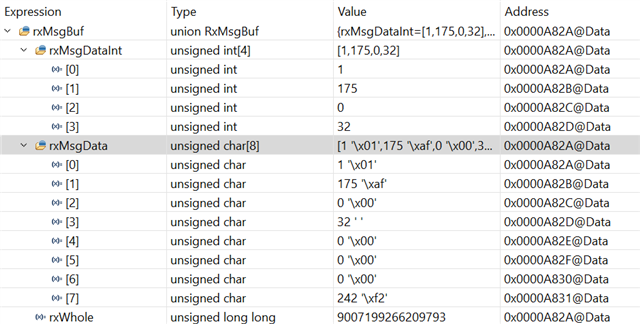
The values shown in rxMsgData (unsigned char, or 0 - 255 if look as numbers) and the rxWhole (uint64_t) seems reasonable to me.
But I don't understand why the rxMsgDataInt has 4 entries which is same as the first 4 of the rxMsgData. I was expecting it interprets each 2 bytes together, and get 4 integers from the 8 bytes data, which should be different values compared to the way rxMsgData interprets. Their address in memory also make me confused since it looks like the address gap among the array members of uint16_t rxMsgDataInt[4] is the same as that of unsinged char rxMsgData[8] (increment is 1 for both cases).
Could you share you advice that what I missed? Thanks.
Regards,
Wei