


Part Number: TMS320F28P650DK
Tool/software:
Hi,
I am trying the code provided in this link https://software-dl.ti.com/codegen/esd/cgt_public_sw/C2000/22.6.0.LTS/README.html to test MMACF32||MMOV32 usage.
The code looks like this (simplified):
// result, buff[], and coef[] are float
interrupt void Cla1Task1(void)
{
result = 0.0f;
int16_t i;
#pragma UNROLL(20)
for (i = 20; i > 0; i--)
{
buff[i] = buff[i-1];
result += coef[i] * buff[i];
}
result += coef[0] * buff[0];
}
and dissasembly shows this:
0x00008078 7FA00000 MNOP 0x0000807A 7FA00000 MNOP 0x0000807C 7F600000 MDEBUGSTOP 0x0000807E 7FA00000 MNOP 0x00008080 7FA00000 MNOP 0x00008082 7FA00000 MNOP 0x00008084 740089A6 MMOVD32 MR0, @0x89a6 0x00008086 73D089D0 MMOV32 MR1, @0x89d0, UNCF 0x00008088 7C000010 MMPYF32 MR0, MR0, MR1 0x0000808A 77C30000 MADDF32 MR3, #0x0, MR0 0x0000808C 73D089CE MMOV32 MR1, @0x89ce, UNCF 0x0000808E 740089A4 MMOVD32 MR0, @0x89a4 0x00008090 049089CC MMPYF32 MR2, MR0, MR1 || MMOV32 MR1, @0x89cc 0x00008092 740089A2 MMOVD32 MR0, @0x89a2 0x00008094 349089CA MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89ca 0x00008096 740089A0 MMOVD32 MR0, @0x89a0 0x00008098 349089C8 MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89c8 0x0000809A 7400899E MMOVD32 MR0, @0x899e 0x0000809C 349089C6 MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89c6 0x0000809E 7400899C MMOVD32 MR0, @0x899c 0x000080A0 349089C4 MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89c4 0x000080A2 7400899A MMOVD32 MR0, @0x899a 0x000080A4 349089C2 MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89c2 0x000080A6 74008998 MMOVD32 MR0, @0x8998 0x000080A8 349089C0 MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89c0 0x000080AA 74008996 MMOVD32 MR0, @0x8996 0x000080AC 349089BE MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89be 0x000080AE 74008994 MMOVD32 MR0, @0x8994 0x000080B0 349089BC MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89bc 0x000080B2 74008992 MMOVD32 MR0, @0x8992 0x000080B4 349089BA MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89ba 0x000080B6 74008990 MMOVD32 MR0, @0x8990 0x000080B8 349089B8 MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89b8 0x000080BA 7400898E MMOVD32 MR0, @0x898e 0x000080BC 349089B6 MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89b6 0x000080BE 7400898C MMOVD32 MR0, @0x898c 0x000080C0 349089B4 MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89b4 0x000080C2 7400898A MMOVD32 MR0, @0x898a 0x000080C4 349089B2 MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89b2 0x000080C6 74008988 MMOVD32 MR0, @0x8988 0x000080C8 349089B0 MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89b0 0x000080CA 74008986 MMOVD32 MR0, @0x8986 0x000080CC 349089AE MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89ae 0x000080CE 74008984 MMOVD32 MR0, @0x8984 0x000080D0 349089AC MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89ac 0x000080D2 74008982 MMOVD32 MR0, @0x8982 0x000080D4 349089AA MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89aa 0x000080D6 74008980 MMOVD32 MR0, @0x8980 0x000080D8 349089A8 MMACF32 MR3, MR2, MR2, MR0, MR1 || MMOV32 MR1, @0x89a8 0x000080DA 7A000BD2 MMPYF32 MR2, MR0, MR1 || MADDF32 MR3, MR3, MR2 0x000080DC 7C20002F MADDF32 MR3, MR3, MR2 0x000080DE 74F089D0 MMOV32 @0x89d0, MR3 0x000080E0 7FA00000 MNOP 0x000080E2 7FA00000 MNOP 0x000080E4 7FA00000 MNOP 0x000080E6 7F800000 MSTOP 0x000080E8 7FA00000 MNOP
When I build with optimizations enabled (C2000 TI v22.6.2.LTS), I see that the compiler tries to optimize this loop using MMACF32 || MOV32 instructions.
However, because my arrays buff[] and coef[] are placed contiguously in memory (buff ends at 0x89A6 and coef starts at 0x89CE), the first instruction that reads buff[19] uses an MMOVD instruction. This instruction not only reads but also writes the value to the next memory location, which ends up overwriting coef[0] with buff[19].
As a result, my coefficients get corrupted.
Here you can see the coefficient loaded:
float aux_coef[20] = { -0.000424f,
-0.002720f,
-0.006804f,
-0.008649f,
0.000000f,
0.027512f,
0.075345f,
0.133183f,
0.181255f,
0.200000f,
0.181255f,
0.133183f,
0.075345f,
0.027512f,
0.000000f,
-0.008649f,
-0.006804f,
-0.002720f,
-0.000424f,
0.0f};
and the coefficient after running the code:
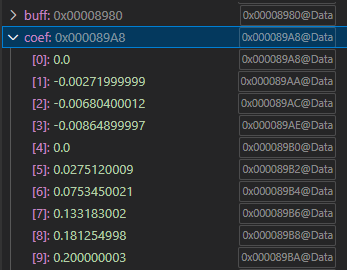
Question:
-
Is this behavior expected with
MMOVDwhen arrays are back-to-back in memory? -
Is there a recommended way (pragma, compiler option, or memory alignment) to prevent this overwrite when using CLA optimization?
Thank you!
Sebastian Glas.
