


There is a problem connected with an asembler instructions execution time in my program. As described in the "TMS320C28x CPU and Instruction Set Reference Guide" (SPRU430E), such commands as "PUSH ARn:ARm" and "MOV AX,loc16" (for example) should be execute for 1 cycle:
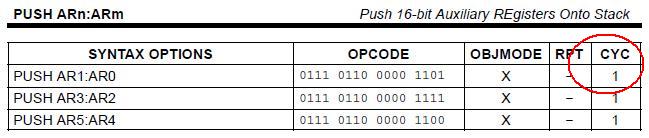

But in practise i have different time of execution:
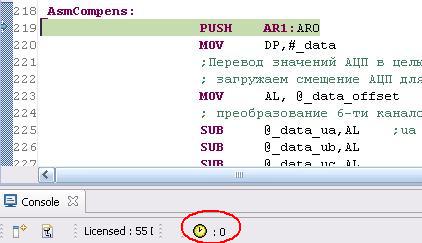
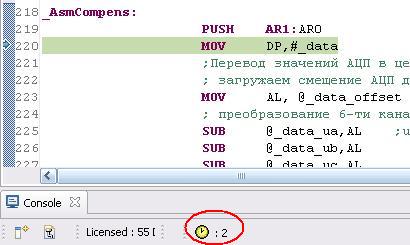

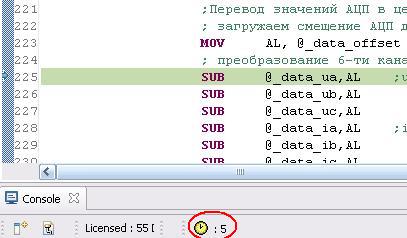
Such time differences appears not only in this commands. What is the reason for this differences?


