Part Number: TMS320F28377S
Hello,
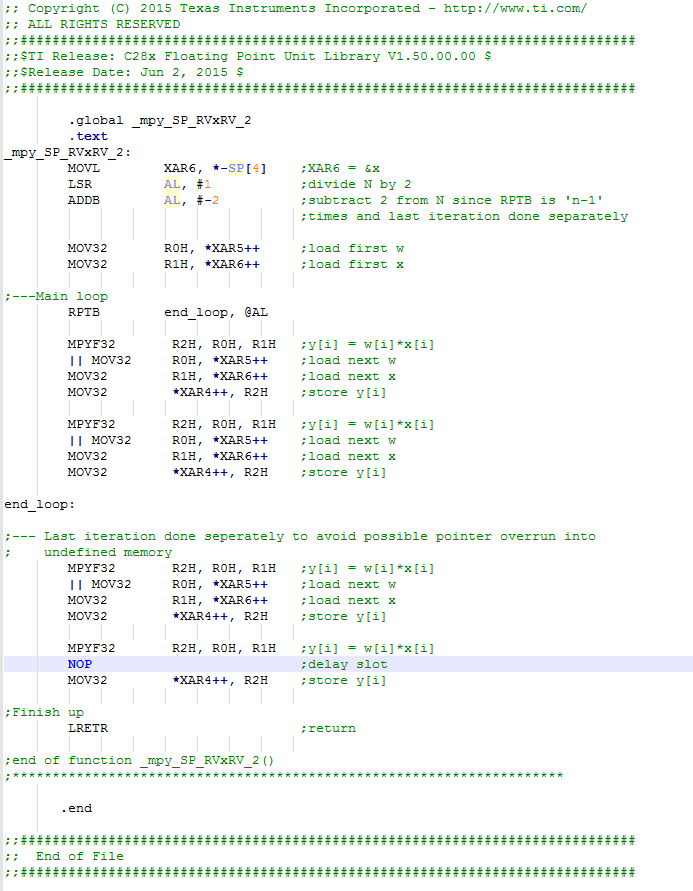
FPU library provides an C callable assembly function of vector multiplication for element wise(dot product, related code snippet is given as screenshot in the end of the thread). I'm also looking for a C callable assembly of vector multiplication according to figure 1 which gives one single element at the end.

figure 1. Vector Multiplication
The provided vector multiplication function in the FPU library has the following function name: void mpy_SP_RVxRV_2(float32 *y, const float32 *w, const float *x, const Uint16 N)
I'm looking for something like this : float32 function_name(const float32 *w, const float *x, const Uint16 N)
there will be a return which gives the summation of the all element wise vector multiplication.