


Part Number: TMS320F280049
Hi,
On the top of TMS320F28004x datasheet (PSRS945E), 1.1 Features, it says;
– Trigonometric Math Unit (TMU)
– 3×-cycle to 4×-cycle improvement for common trigonometric functions versus software libraries
– 13-cycle Park transform
My customer is asking;
Q1) What does the “Park transform” exactly mean here?
Q2) Which TMU supported instructions (see below) are used to perform the “Park transform” above?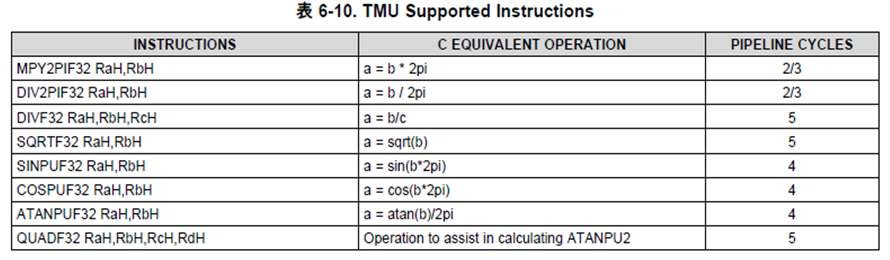
Q3) What makes this 13 cycle?
Thanks and regards,
Koichiro Tashiro
