


Hi
We have an in production product that causes us some problems. It is based on the TI 28377s microcontroller.
We are using TI v18.1.4.LTS toolchain, SYS/BIOS 6.75.0.15, XDCtools 3.51.1.18_core.
If I am using the JTAG everything seems to be working fine, so maybe the GEL file is doing some magic we are not. It seems the error comes and goes with code changes, so the error is not always located in this piece of code.
I have managed to reproduce the error by having a while loop early in the boot process (WD disabled) then connecting to the running target and continue the "boot" process. With this I managed to catch the NMI interrupt and look at the call stack. Below is a picture of this:
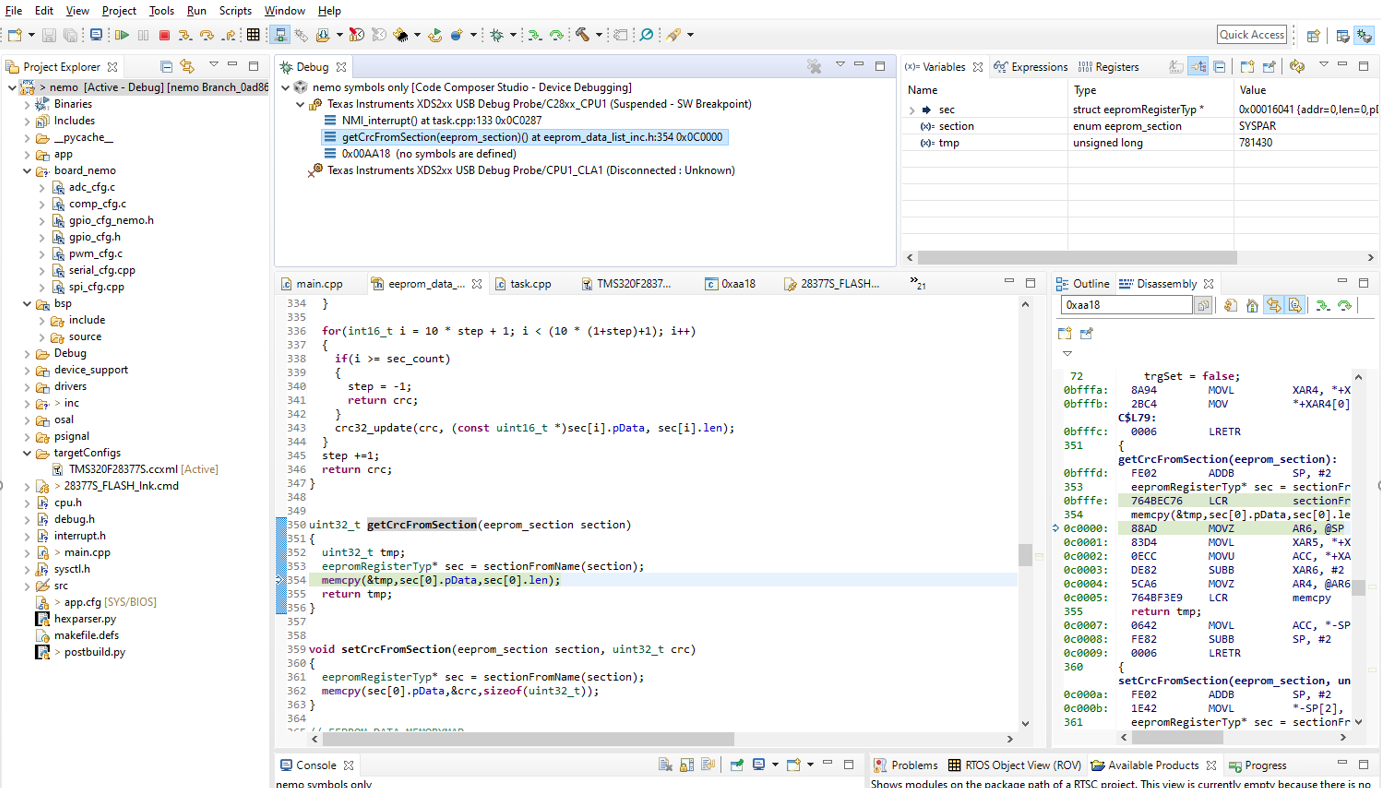
As you maybe have noticed is that the failure seems to occur around the memcpy in getCrcFromSection() function. This normally works, if I use the JTAG with the standard 28377s gel file to init the CPU, so this code should be fine.
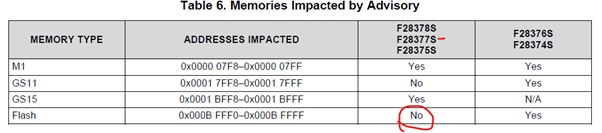
What I have noticed is that this code is placed across the 0x000C 0000 boundary, which is the beginning of flash bank 1. Currently we have one big flash range in our linker cmd file that covers both flash bank 0 and 1 (this will probably change). I have looked at the errata for the CPU (sprz422i) for the advisory on "Memory: Prefetching Beyond Valid Memory" and according to this, there are not limitations on the boundary between these two flash banks for this CPU.
We have initialized both flash banks with the InitFlash_Bank1() and InitSysCtrl() ( latter calls InitFlash_Bank0() )
I have tried to set a breakpoint just before the sectionFromName() and the entire call stack and variables seems fine. When I step over the sectionFromName/memcpy(), the NMI interrupt is triggered and the call stack looks as pictured earlier.
Is what we are seeing a pipeline issue related to the above mentioned errata or something else?
An update:
I have tried manually placing the getCrcFromSection() function before and after the boundary between flash bank 0 and 1.
If I completely avoid the 0x000B FFF0 - 0x000B FFFF range, which should NOT be necessary for this CPU according to the errata, everything seems to be working fine.
If I place part of the getCrcFromSection() function in the above range, a NMI exception occurs.
Is the errata wrong?

