Part Number: MSP430F2619
Other Parts Discussed in Thread: MSP-EXP430F5529LP
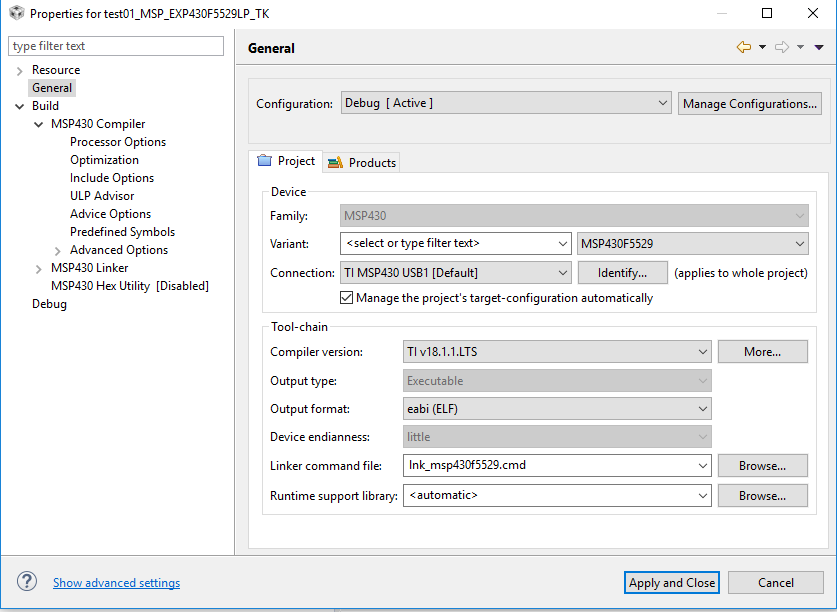
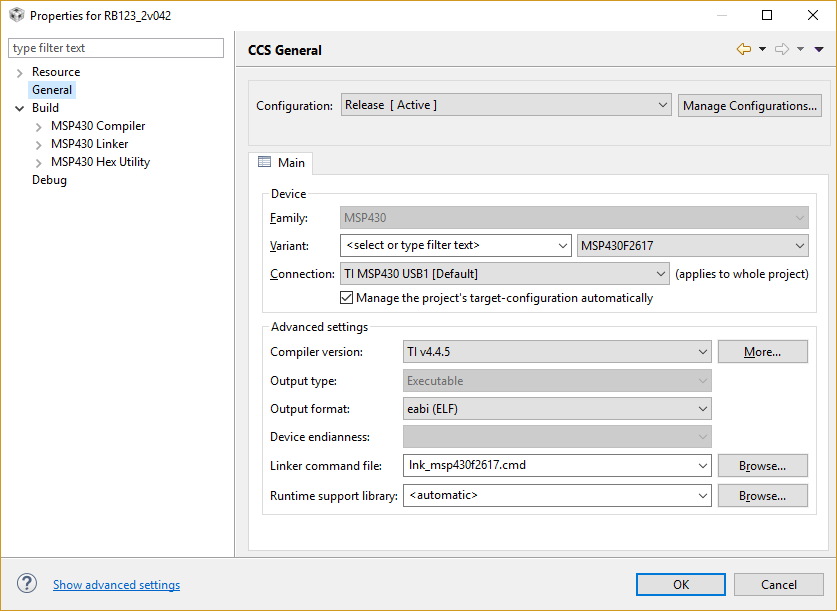
Tool/software: Code Composer Studio
With CCS v6.1.2 a loop of 128 double precision floating point iterations of math.h functions runs in about 2secs.
The same loop complied in CCS v7.4 with math.h runs in about 8-9secs. Both versions are release builds and --fp_reassoc is off for both versions.
What could be causing v7.4 floating point code (math.h functions) to run 4x slower?
Aaron