Other Parts Discussed in Thread: EK-TM4C1294XL
Hello,
I'm using EK-TM4C1294XL evaluation kit to measure delay between rising edge on PB3 pin and interrupt response. Here's the code:
#include <stdint.h>
#include <stdbool.h>
#include "inc/hw_memmap.h"
#include "inc/hw_types.h"
#include "inc/hw_ints.h"
#include "inc/hw_nvic.h"
#include "inc/hw_gpio.h"
#include "driverlib/interrupt.h"
#include "driverlib/debug.h"
#include "driverlib/fpu.h"
#include "driverlib/gpio.h"
#include "driverlib/pin_map.h"
#include "driverlib/sysctl.h"
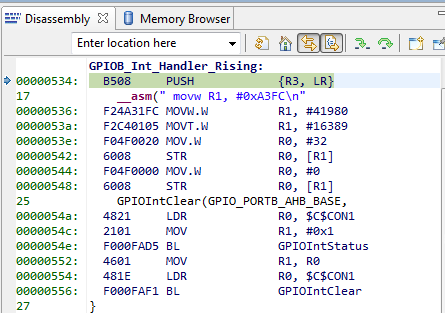
void GPIOB_Int_Handler_Rising(void)
{
__asm(" movw R1, #0xA3FC\n" /*load lower part of GPIOC port addr to r1*/
" movt R1, #0x4005\n" /*load upper part of GPIOC port addr to r1*/
" mov R0, #0x20\n" /* load "on" pin value to r0 */
" str R0, [R1]\n" /* write value of r0 to GPIOC port */
" mov R0, #0x0\n" /* load "off" pin value to r0 */
" str R0, [R1]\n" /* write value of r1 to GPIOC port */
);
GPIOIntClear(GPIO_PORTB_AHB_BASE,
GPIOIntStatus(GPIO_PORTB_AHB_BASE, true));
}
void main(void)
{
uint32_t sys_clk = SysCtlClockFreqSet((SYSCTL_XTAL_25MHZ |
SYSCTL_OSC_MAIN |
SYSCTL_USE_PLL |
SYSCTL_CFG_VCO_480), 120000000);
SysCtlPeripheralEnable(SYSCTL_PERIPH_GPIOB);
while(!(SysCtlPeripheralReady(SYSCTL_PERIPH_GPIOB)));
SysCtlPeripheralEnable(SYSCTL_PERIPH_GPIOC);
while(!(SysCtlPeripheralReady(SYSCTL_PERIPH_GPIOC)));
FPUStackingDisable();
GPIOPinTypeGPIOOutput(GPIO_PORTC_AHB_BASE, GPIO_PIN_5);
GPIOPadConfigSet(GPIO_PORTC_AHB_BASE, GPIO_PIN_5, GPIO_STRENGTH_8MA_SC,
GPIO_PIN_TYPE_STD_WPD);
GPIOIntRegister(GPIO_PORTB_AHB_BASE, GPIOB_Int_Handler_Rising);
GPIOIntTypeSet(GPIO_PORTB_AHB_BASE, GPIO_PIN_3, GPIO_RISING_EDGE);
GPIODMATriggerEnable(GPIO_PORTB_AHB_BASE, GPIO_PIN_3);
GPIOIntEnable(GPIO_PORTB_AHB_BASE, GPIO_INT_PIN_3);
IntEnable(INT_GPIOB);
while(1);
}
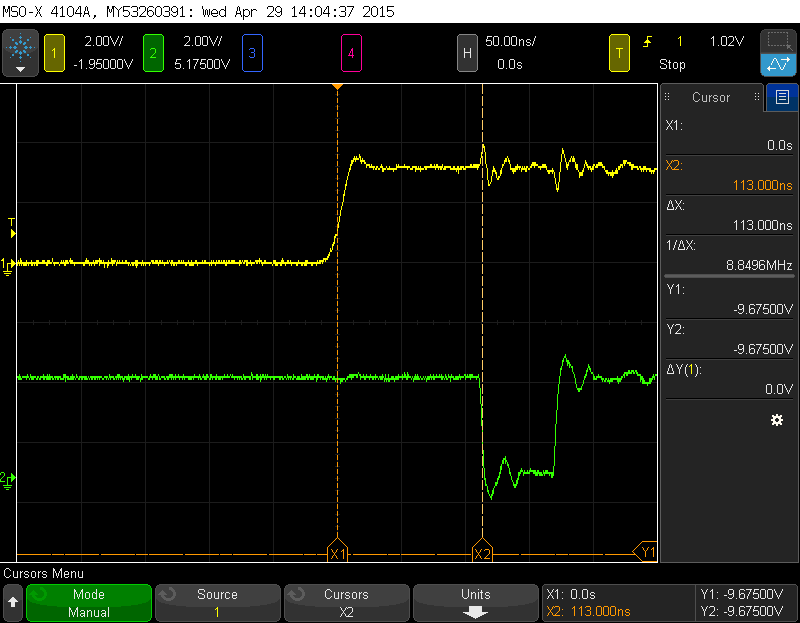
This is what I see on oscilloscope:
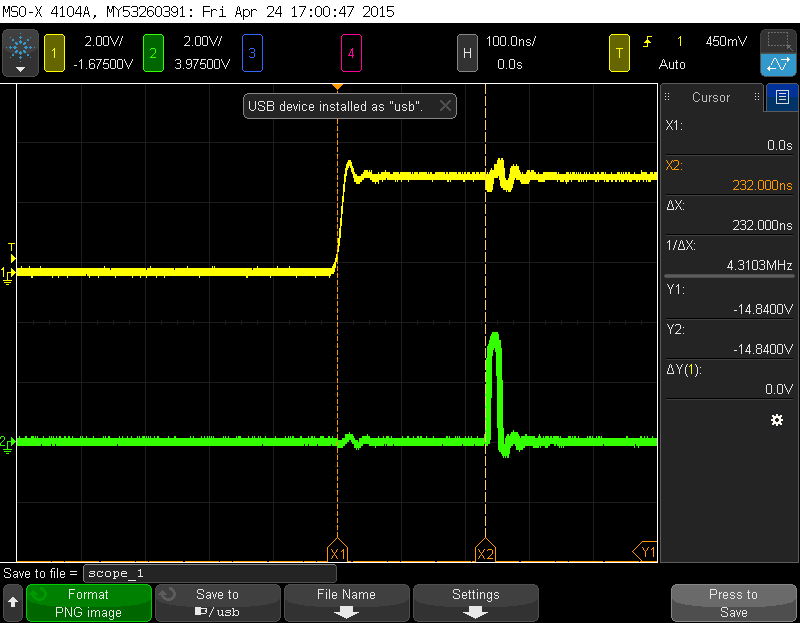
As far as I'm aware, it takes twelve clock cycles to launch interrupt service routine, my assembler code takes another five clock cycles (four to execute and one cycle for gpio pin rise delay) to execute. Together we have seventeen to eighteen(if rising edge on PB3 arrives when system clock is high) clock cycles. System clock runs at 120 MHz frequency, so its period is 8,333 ns. This gives 18 * 8,333 = 150ns of the delay. But on the scope I see about 230 ns of the delay, so where's missing 80 ns?