Tool/software:
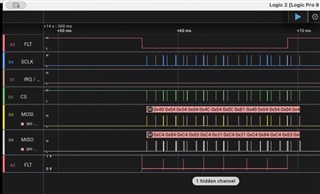
We have custom hardware talking with the DRV8889(latest SI rev of the chip).
We have verified normal operation, by stepping and stalling the motor. Communication packets look good and have been verified.
Open load detection is disabled in our case.
Observation:
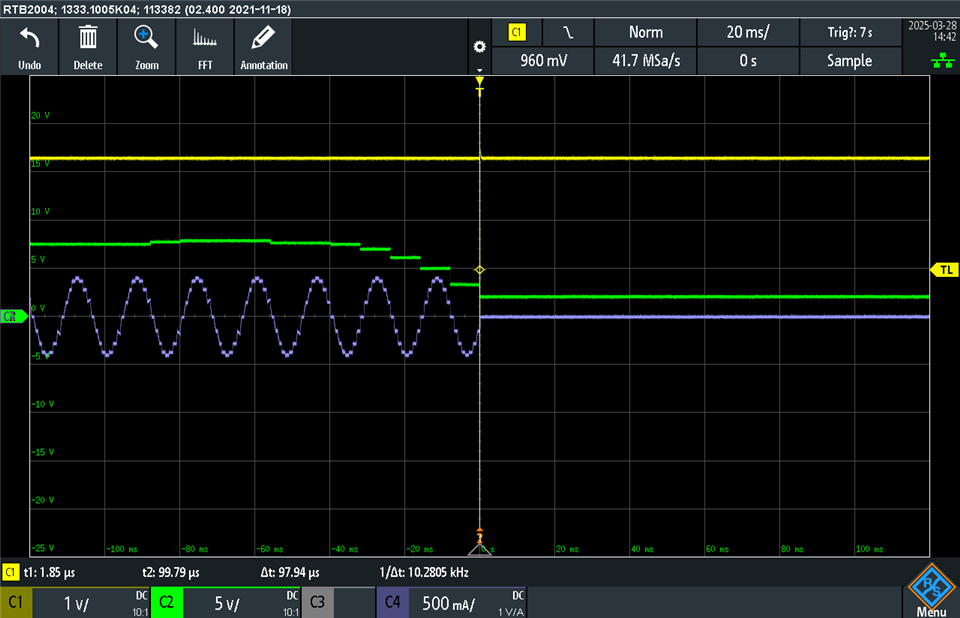
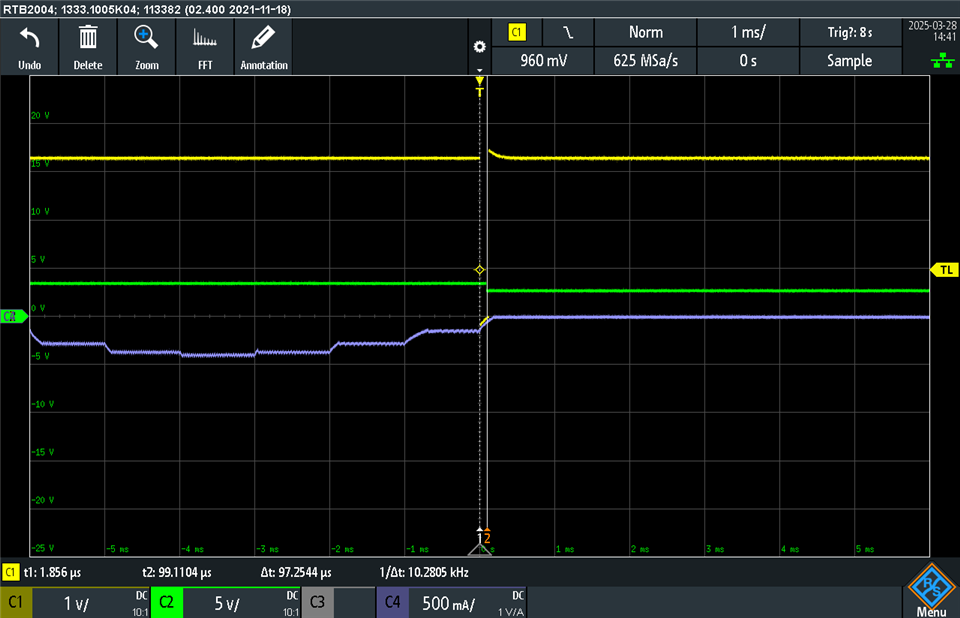
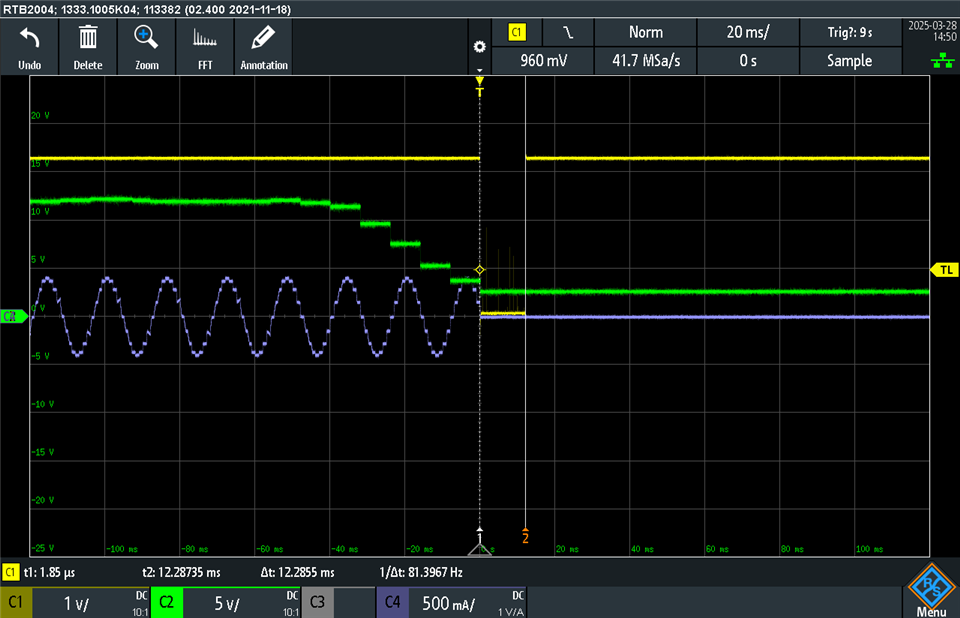
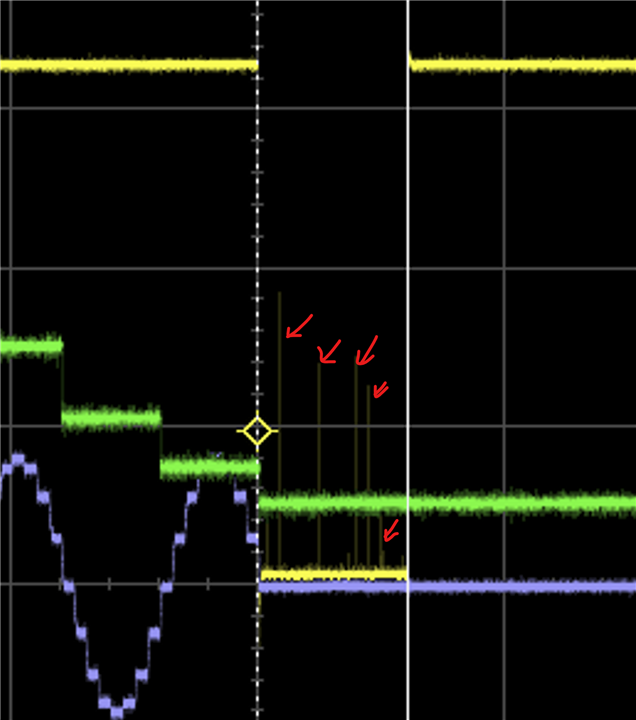
- When a stall condition is detected, it lowers the Faultline, which is an ISR into our host software.
- Host software detects the fault line go low(or high) and send a command to clear the latched faults.
- A readback from the fault status register, 1ms. later, shows the stall bit still set.
- However a clear fault issued again ~250ms later, clears the fault
Question:
Is there a minimum time for the DRV8889 for the stall to clear? Is yes, where is this time specified. If no, how do we calculate this?
Additional info:
The register values we use are below:
FAULT: 0xA5
DIAG1: 0x00
DIAG2: 0x00
CTRL1: 0x83
CTRL2: 0x0F
CTRL3: 0xA4
CTRL4: 0x31
CTRL5: 0x18
CTRL6: 0x0C
CTRL7: 0x00
CTRL8: 0x03