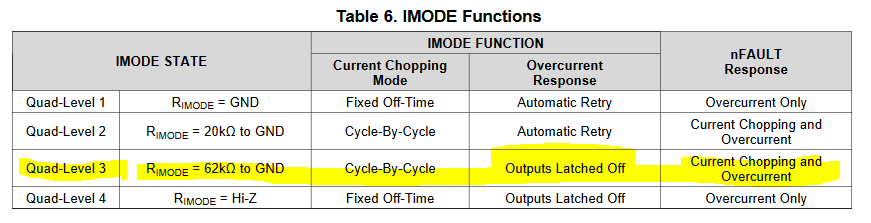
I'm driving a 12VDC motor using a DRV8876 controlled by an atmega328p and find when using a high PWM duty cycle coming out of my PID controller, the driver will tend fault on startup (either right off the bat, or after a few stops and restarts). If I limit the PID range to around +/-70, it doesn't seem to fault.. but when I get above that, it does. I have it configured for cycle-by-cycle/latched output (quad-level 3) mode. I'm certain its not current-chopping since I can cause that to occur by changing Vref and the fault that appears clears on its own. With the high PWM, when it faults and stays faulted and the only way I've been able to clear the condition is to power cycle (remove and reapply Vm). Looking at Table 7, I'm not sure what the cause is:
When the atmega detects the fault (one that has lasted longer than 500 ms and there's been no change in motor encoder reading .. this is to avoid messing up working current-chopping routine) then to clear the fault, it brings nSleep High, waits 2ms, and brings it Low. nFault clears after doing this. However, the driver still seems to have its outputs disabled. My understanding is that with fault cleared (and the condition removed), operation would resume. Reviewing Table 7, I would think both Vulvo or Vcpuv would clear on its own pretty quickly since the motor is stopped and the power supply should recover. A TSD would clear when the temperature drops, but I don't think its TSD since it can happen right on startup. The only thing perhaps then is OCP, but doesn't that clear on its own as well? This issue doesn't occur when driving smaller motors.
And lastly, this issue didn't crop up when using smaller motors that draw less current. I can run those at full PWM with no issue.