Hi Ti
gpu version is 1.13.5776728
SDK 7.2
Linux
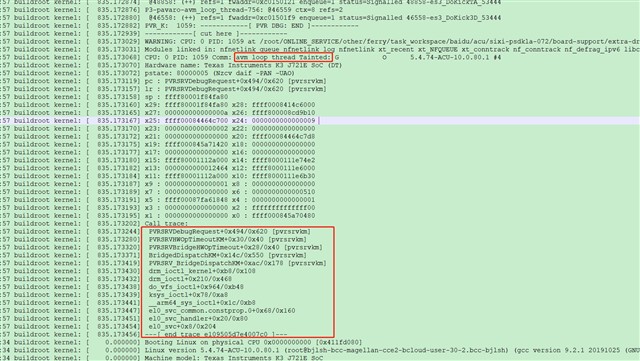
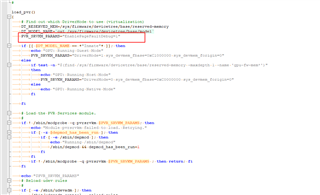
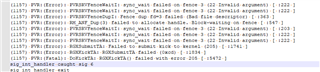
The glBindFramebuffer coredump problem reappears. The current situation is the same as the original problem. See the link below for relevant information
According to the last communication, we collect the PVR related log
run:
pvrdebug -loggroups main,mts,hwr
exceute app,coredump