


Other Parts Discussed in Thread: AM62A74, AM68A, AM62A3, AM69A
I made a model and what to understand how fast it can run on an AI accelerated device like the AM62A.
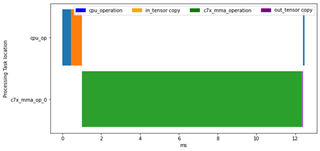
I see variations in performance based on which scripts I use, and I don’t see identical performance to what the cloud tools like Model Analyzer/Model Selection Tool show. Why is this?
How can I understand the performance of my model better?


{kind=link}