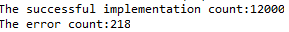Hi,
Test Case: ES 2.0 EVM board (master) to ES 2.0 customer board (slave) SPI transaction overnight test.
Test Content: Both master and slave send known data to each other to identify whether the received data is correct, if both master and slave receive the incorrect data the error count will increase, otherwise, the successful count will increase.
Question 1: Why does the performance between SPI with DMA and without DMA have a difference in error count? (I use the same code in the two cases)
As the picture shows, SPI without DMA didn’t occur the error that both master or slave received the incorrect data.
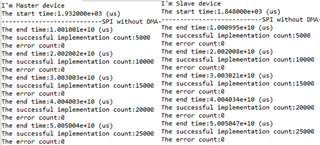
But SPI with DMA has this error, As the picture shows. In here, the error count is different between the master and slave because the master receives correct data but the slave does not in a certain transaction.
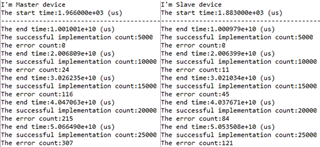
Question 2: According to the above two pictures, why the implementation time of SPI with DMA is almost the same as SPI without DMA? for my understanding that SPI with DMA should be quicker.
The implementation time = the end time - the start time
for example, the successful implementation count = 25,000 in SPI with DMA on the slave side
The implementation time = 5.0535e10(us) - 1.883e3(us) ≅ 50,535 (s) ≅ 14.03 (hrs)
in SPI without DMA on the slave side
The implementation time = 5.0050e10(us) - 1.848e3(us) ≅ 50,050(s) ≅ 13.9 (hrs)