Hi,
I would like to ask some questions on software breakpoint implementation.
Observation:
One can add/remove/modify software breakpoints after the executable code has been loaded into memory, or even after the program is halted as another breakpoint.
↓
Conclusion:
Software doesn’t require rebuild or re-compilation.
Question:
Then how is breakpoint implemented? Consider the most naïve implementation that breakpoint is implemented as adding several lines of special instruction before the line of breakpoint, this certainly required recompilation and re-linking. Clearly, this possibility has been ruled out by our conclusion above.
There might be another two alternatives:
Alternative I:
“Patching” the memory where the code resides:
Note:
One can either patching all breakpoint lines at once, or patch only the next two possible branching target breakpoints when its parent node has been reached (see the semantic tree below). I don’t see any difference between them and it should up to the implementation.
Alternative II:
Designate two special registers in the CPU for implementing this.
Why would we require two of them rather than one? This is basically because each branching, executed or not, can lead to two different new program counters / addresses - In data structure, two child nodes of a binary tree.
Case I:
→
SW 1
Line 1
Line 2
SW 2
Line 3
Line 4
Line 5
SW 3
Line 6
The characteristic of this case is that the order of execution is linear. Therefore, the only possible breakpoint is the next, so upon halting at SW 1, the debugger has to tell the CPU, through emulator for TI chips or directly writes to CPU registers on desktop PC, the next breakpoint location by writing to either of the two dedicated CPU breakpoint target registers:
After the user pressed “run” again, the CPU would compare each new program counter with SW1, and halt if matches.
Case II:
SW 0
value = expression
Case value
→
SW 1
Switch 1
{
…
}
SW 2
Switch 2
{
…
}
SW 3
Switch 3
{
…
}
.
.
.
SW 1000
Switch 1000
{
…
}
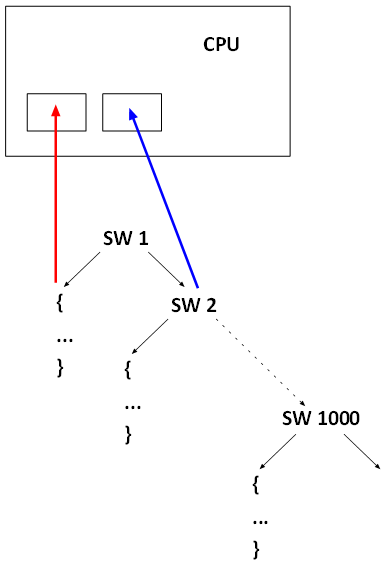
To exclude the case of computed value before running (known at compilation), we further stipulate that value is only possible to be known at run-time, for example, if expression contains at least one user input term.
In this scenario, upon finishing of SW 0, there might be as many as 1000 new target address. But this is only an illusion, since the semantic tree is always binary. Therefore, storing two possible PCs as shown in the diagram below is enough. Each time a new breakpoint is reached, the debugger-emulator should update the contents of these two registers
With this scheme the same resulting can be achieved without “patching” the memory.
Advantage of alternative II.
The advantage is that it doesn’t modify code itself, thus eliminating the case above. However, since for each instruction the CPU needs to do the comparison between values in these two registers, two comparisons in total, this might result in a severe performance penalty if the circuit for comparison is not fast enough.
Conclusion:
Since self-modified code is far less common the normal case where code are not changeable during execution, I think alternative I, “patching memory”, should be the actual implementation on all platforms (processor + IDE).
My question is how is software breakpoint in C6000 actually implemented? Is it solely based on alternative I? Or I, or is a mixture of them? I wish to get a detailed answer on this.
Thanks,
Zheng