


Hi everybody,
We are developing a product where CC2640 is conected by SPI to a main MCU (MKL27 from Freescale). We have implemented NPI over SPI (as described, for example here: processors.wiki.ti.com/.../Cc2640_Adding_a_UART_or_SPI_driver_to_a_Sample_Project) to solve communication between them. SPI/NPI communication is bidirectional: both chips can read and write on bus at any given time (if it is not busy, of course).
We are having some strange problems: communication starts working, but it fails after some minutes (https://e2e.ti.com/support/embedded/tirtos/f/355/p/458078/1654073#1654073). Revising and analyzing TL protocol, we have found some issues we don't understand.
To expose the first one, consider the case when slave (CC2640) writes. The timing diagram documented in in http://processors.wiki.ti.com/index.php/Cc2640_Adding_a_UART_or_SPI_driver_to_a_Sample_Project#TL_Protocol shows that "The data transfer is ended by the master raising MRDY followed by the slave raising SRDY. "
Analyzing the code, we see that raising MRDY and SRDY are independent events triggered by the corresponding callbacks in the corresponding SPI driver implementation of each driver (that is, the driver in the master MCU raises MRDY when it detects transaction finished, and the driver in the slave (CC2640) raises SRDY when it detects transaction is finished).
Moreover, if MRDY raising was detected in the slave side before the transaction is marked as finished in its side (that is also the event that raises SRDY), then the function SPICC26XXDMA_transferCancel() would be called to cancel transaction. So we don't understand that order (MRDY raising before SRDY raising) in that diagram. Also, we have made some captures using a logic analyzer, and we see that MRDY is lowed and raised a few microseconds after the corresponding SRDY edges:
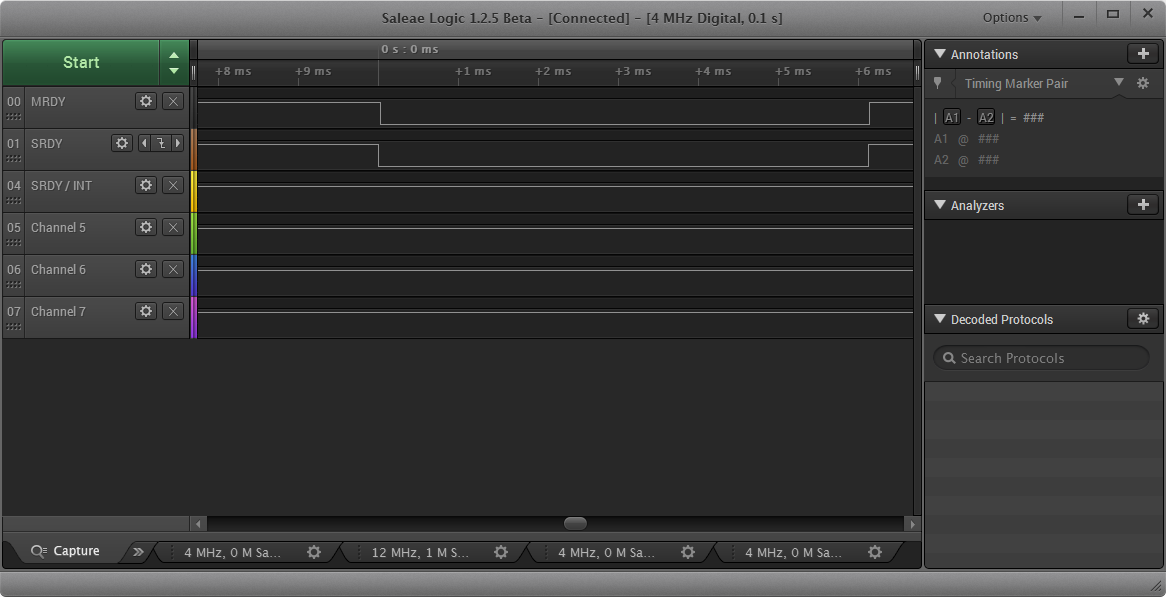
In any case, as said, the raising edges are completely independent in our code. In fact, using a breakpoint we have observed that after some minutes raising MRDY must be happened first, because SPICC26XXDMA_transferCancel() is called to cancel a current NOT NULL transaction.
Could you explain me this issue of the diagram? Should we do something to synchronize in any way the raising edges of MRDY/SRDY? In that case, which of them should be trigered first?.
Thank you very much.
Regards.
José Antonio Martínez.





){kind=link}