


We are finding a rather difficult to debug (hard to reproduce) issue with our device nodes.
Sometimes a devices in a network simply looses their connection to the gateway. The device is still responsive (reacts to sensor inputs) but we don't get any data through our network.
Because it happens only once in a while (maybe even weeks) it is quite impossible to debug because you never know which device is going to fail in a network (mostly 20-30 devices in a network). Resetting the device is the only way out of this mode and then it works ok again.
Now what I did try today with a device that was stuck in this 'mode' was look at the network traffic with a sniffer and found out that it was still sending out data but with an 'invalid' destination PAN (0xFFFF) and invalid short address (0xFFFF). Destination itself was still correct. (see screenshot from Wireshark). Before this happened these values were correct of course (0x6833 and 0x0001).
So it looks like either the MAC layer or the sensor application loose the values for destination PAN and short address.
Our application is based on DMM sensor OAD with SDK5.10 but this was also happening in SDK4.30.
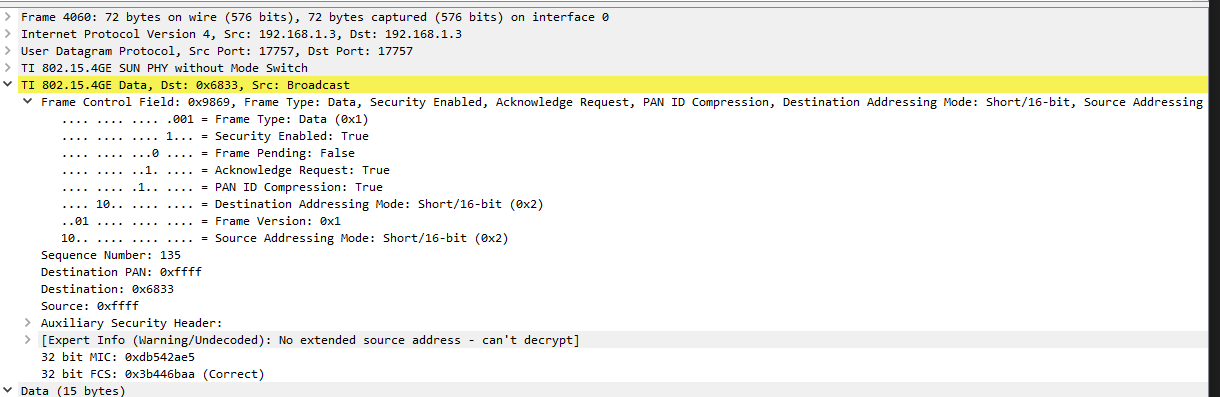
any suggestion as to why a device can 'loose' the association data?
The only two places I found in code where these values are set are: disassocCnfCb and disassocIndCb but there all the data gets reset and then destination address would also be cleared which is not the case.

