


Dear TI,
I am using the CC3220 Launchpad with 20 MHz SPI connection to transceiver. I ported the application from STM32 architecture with HAL drivers.
For the transceiver we need to do some time-critical tasks (with mainly small SPI transfers) in between reception of transmission of frames of the transceiver. It turns out that the current implementation takes too long to be on time.
The CC3220 uses a higher SPI CLK (20 MHz) than the STM32 (18 MHz), but still it takes more time on the CC3220 than STM32. When analyzing the transfers, it turns out that the overhead of SPI transfer for my current implementation is too high. An example is shown below for SPI write command where first a header is sent, then a pretty long pause and then the payload (Blue is CS, Yellow is SPI CLK):
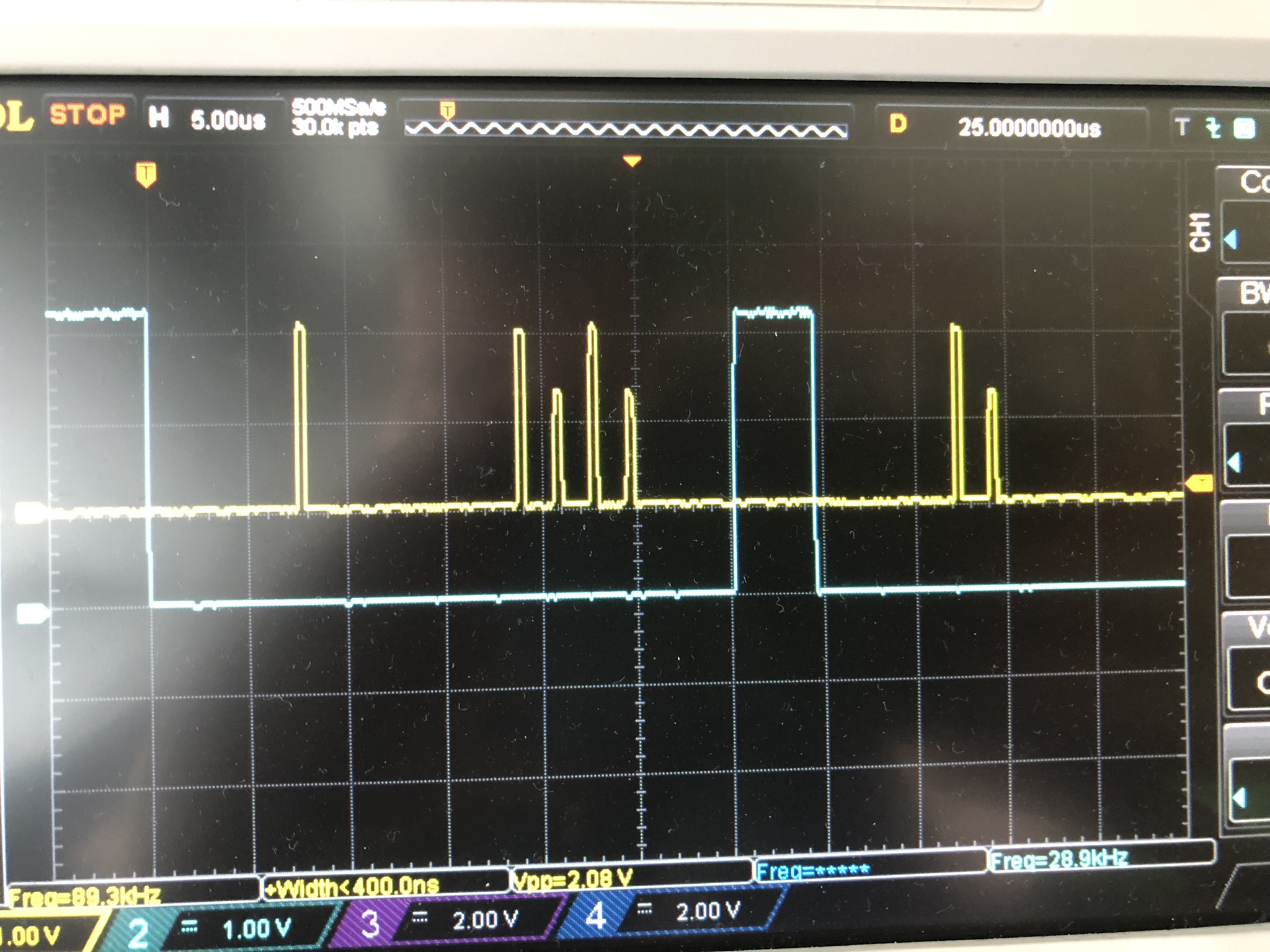
As you can see there are a few things that mainly determine the total transfer time: (1) time between CS and start of transmission, (2) time between end of header and start of payload transmission and (3) time between end of payload transmission and CS. In this case, these times are (1) ~7 us, (2) ~10 us and (3) ~5 us. In the STM32 example these are (1) ~2 us, (2) ~2.5us and (3) ~1.5us.
So my question is: what would be the best way to implement this? My current implementation looks like this:
transaction.count = (uint32_t) headerLength;
transaction.txBuf = (void *) headerBuffer;
transaction.rxBuf = NULL;
SPI_Transaction transaction2;
transaction2.count = (uint32_t) bodyLength;
transaction2.txBuf = (void *) bodyBuffer;
transaction2.rxBuf = NULL;
/**< Put chip select line low */
GPIO_write(CS_GPIO, GPIO_PIN_RESET);
/* Perform SPI transfer of header */
bool transferOK = SPI_transfer(spi, &transaction); /* Send header in polling mode */
bool transferOK2 = SPI_transfer(spi, &transaction2); /* Send body in polling mode */
/**< Put chip select line high */
GPIO_write(CS_GPIO, GPIO_PIN_SET);
This implementation is "code-wise" similar to the STM implementation. I have also tried to do one SPI transfer, and use malloc and memcpy to create a signle buffer for transaction. This way you will not have a gap between the two transmission, but you will need more time (~4-5 us extra for 5 bytes as far as I can see now) to do the memory allocation and copy. On the other side it would relax the constraints on the SPI transfer time if I am starting to use DMA (but I want to prevent this extra challenge for now if possible). So the options that I am now considering are:
(1) Use of the hardware CS (and hope that it is a lot faster). One problem however is that the original STM32 application code kind of abused the SPI CS to wake the device up as well. I don't see how I could do something similar in such a configuration.
(2) Use driver lib instead of TI Drivers. The driverlib seem to be very close to hardware registers, so using hardware registers directly would probably not help much. I am still not sure however if I would gain a significant amount of time, and if so: where can I get the gain? I was thinking about the SPICSEnable() and SPICSDisable() functions, but if I see the documentation of the functions I don't think they are very useful
Could you help me considering my best options? There should be a way to reduce the time between CS and SPI_CLK right?
Best regards,
MJ

