Part Number: CC2651P3
Hello,
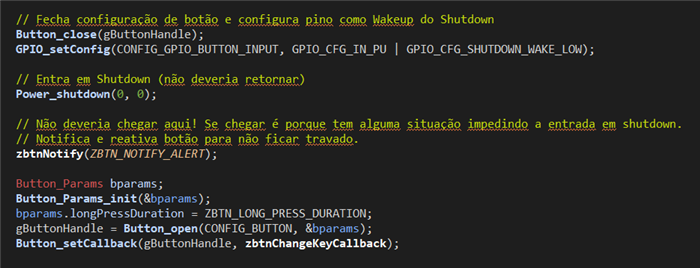
I am developing an application in which my zigbee end-devices stay in shutdown mode for most of the time and only get out from shutdown mode when a button is clicked, Then the device rejoin the network, send an APS packet with APS Ack, and go back to shutdown.
My code is based on the zed_switch example, but was modified to send an APS packet with APS Ack to the coordinator when the button is clicked. I am using the last SDK (simplelink_cc13xx_cc26xx_sdk@7.10.01.24)
Most of time, everything just works, but from time to time, a device loses all network information and I need to recommission the device.
I could reproduce this problem more than once, but only with hard network conditions (pressing many devices at the same time so that they try to rejoin at the same time and at a distance in which some packets may be lost).
I think that something may be triggering a Factory New reset. I do not see any Leave message on the air with rejoin set to false, what would trigger a Factory New reset on the end-device. So it must be something triggered on the end-device alone. In the documentation, I saw that a TCLK exchange failure could do that. But could that happen with a commissioned device that is just rejoining the network? There is some other situation in which a Factory New reset can be triggered in the end-device? Any other idea of what could cause the device to lose the network information?
In my test setup, I had one coordinator and 11 end-devices. In one test that runned for 4 days, I managed to lose 3 end-devices with the following address:
00:12:4b:00:2a:80:41:5c
00:12:4b:00:2a:80:41:6c
00:12:4b:00:2a:80:41:72
I have the sniffer file from this test. How can I send it here?
Last packets from 00:12:4b:00:2a:80:41:5c - Last messages from this device.

Last packets from 00:12:4b:00:2a:80:41:6c - The last packets (APS) could not be decrypted. I don't know why. In almost 70k packets captured, this kind of packet (orange) appears only here.

Last packets from 00:12:4b:00:2a:80:41:72 - After a transmission that appears to be OK, there are packets with Transport Key from the coordinator to the end-device short address, but without response. No more packages to or from this device after that.