Other Parts Discussed in Thread: CC2530
Hello,
I'm facing a strange problem with CC2530.
Before I start, let me point some facts:
- I'm using a proprietary firmware with proprietary protocol (Not Z-STAK nor RF4CE)
- I'm using a proprietary bootloader with UART commands and WIRELESS commands.
- This product is on the market for a couple of years and this issue is happening sporadically.
Here is whats is happening:
When we receive the product for technical assistance, the CC2530 is not working and we start an investigation process. The CC Debugger recognizes the chip and I can read the IEEE Address. So I know the CC2530 is working properly.
We try to connect with the bootloader Over the Air and Over Cable (USART). The bootaloader does not respond.
We procced with a "read flash into hex-file" and compare to a golden hex-file with the same bootloader version and application version.
If I rewrite the bootaloder using CC Debugger, the devices gets full operational again.
This issue happened other times but the investigation process was only made in the last two devices with this problem.
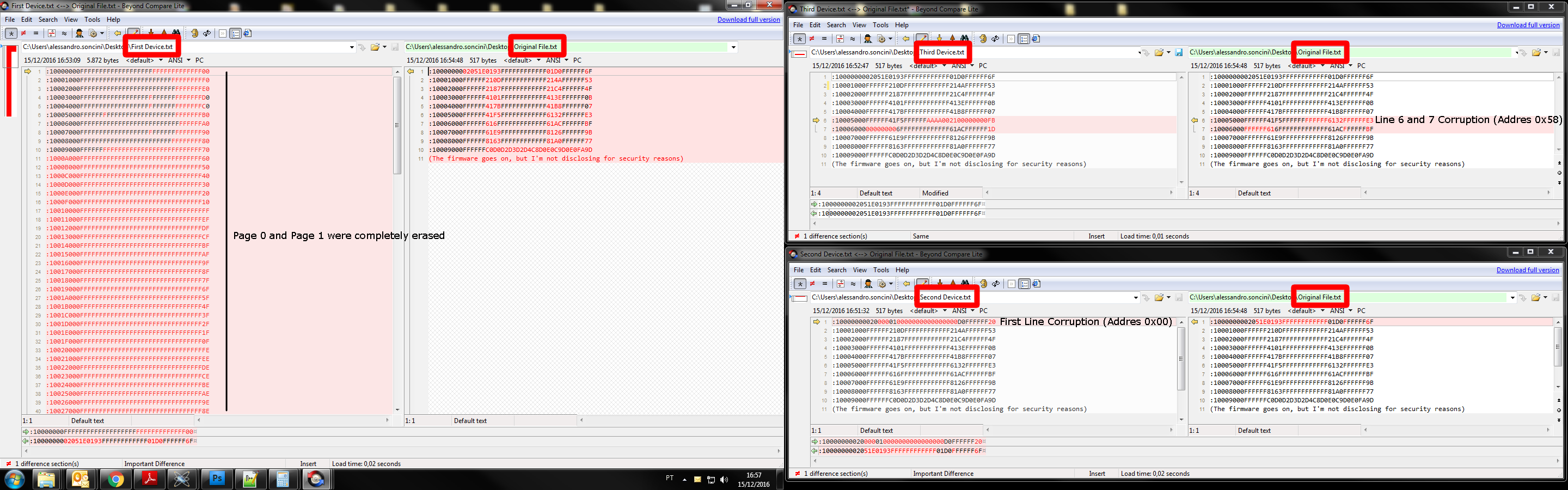
Problematic Device 01:
By analyzing the hex-file we could see that the first 2 pages were erased. The first 2048 bytes were displayed as 0xFF in the hex-file. So it will be 2048 NOPs until the first valid byte appears.
Here is the first line of the problematic hex-file:
:10000000 FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF 00
And here is the first line of the golden hex-file:
:10000000 02051E0193FFFFFFFFFFFF01D0FFFFFF 6F
Problematic Device 02:
By analyzing the hex-file we could see that the 11 bytes of the 16bytes from the first line of the hex-file were different. Not just different, but the bytes were replaced by 0x00. So the first jump will point to address 0x0000.
Here is the first line of the problematic hex-file:
:10000000 020000010000000000000000D0FFFFFF 20
And here is again the first line of the golden hex-file
:10000000 02051E0193FFFFFFFFFFFF01D0FFFFFF 6F
Is it possible that a voltage spike, a brownout (not enough to reset de device) or a current surge could modify the values in the flash or change the values inside the RAM?
When the Problematic Device 01 appeared I thought that It could be an error in the bootloader firmware, but since Problematic Device 02 appeared I'm starting to think that this behavior is not a firmware problem but a CC2530 problem related to an abnormal condition.
Could someone please give me some detailed enlightenment about the behavior of the RAM and FLASH in abnormal condition like over voltage, under voltage, radiated EMI, ripple on the VCC line, etc.
Is there any condition that the problem described above could ever happen?
Thanks.