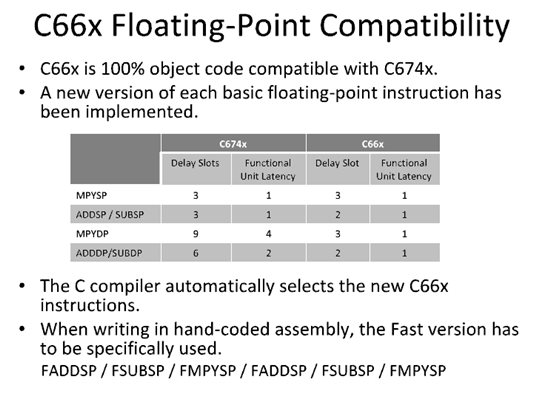
If I want to run some code with float data on 6678, is there any special properity needs to be stated?
I tested the running time of a project with float data calculation on evm 6678 and another 6713 evaluation platform, I found that the effeciency of one core of 6678 is only two
times of 6713. This result didn't fit the description of 6678 in its mannual, which is at lease 4 times. I doubt that I misoperated something, would somebody be kind enough to
help me?
Thanks a lot,
May