Part Number: 66AK2H12
Other Parts Discussed in Thread: SYSBIOS
Tool/software: TI-RTOS
XDCtools 3.32, SYS/BIOS 6.46, CCS 7.4, PDK 4.0.7, NDK 2.25
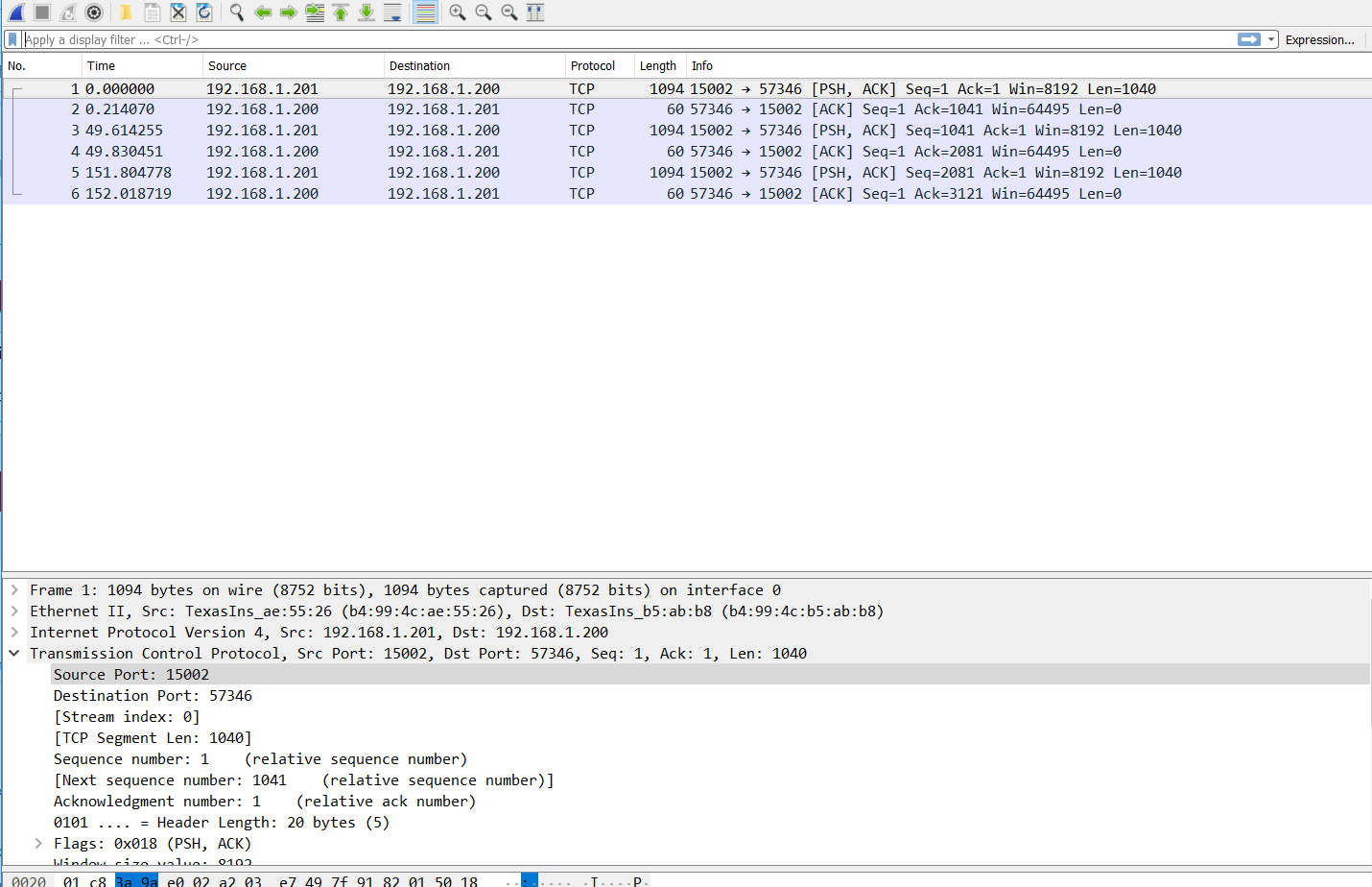
I’ve got two EVMs connected via TCP. On the EVM server I’ve got socket options set for SO_SNDTIMEO and SO_RCVTIMEO of five seconds. I never send anything to this socket but the EVM server sends data out the socket to the client.
I’ve got a Windows10 application that acts like a client to this EVM server and it works as expected. The EVM server sends data out the port and the Win application gets it.
If I replace the Win10 client with the EVM client I have a problem if the data sent from the EVM server is ‘large’. I’ve only got two data points for reference to define ‘small’ and ‘large’; ‘small’ is a stream of 296 bytes and ‘large’ is a stream of 10912 bytes. When I send a ‘large’ stream from the EVM server to the EVM client, the client recv() returns -1 and fdError() gives 54, ECONNRESET. If I send ‘small’ streams of data I get it without and recv() errors.
I am using the Legacy Non-BSD Sockets Interface. I have socket options on the client socket of:
int option = 1; int len = sizeof(option); setsockopt( clientS_, SOL_SOCKET, SO_KEEPALIVE, &option, len ); option = rcvBufSz; setsockopt( clientS_, SOL_SOCKET, SO_RCVBUF, &option, len ); option = sendBufSz; setsockopt( clientS_, SOL_SOCKET, SO_SNDBUF, &option, len );
where rcvBufSz is currently set to 65535 and the sendBufSz is set to 8192.
Any ideas of things I should check?
Mike