Part Number: DP83867E
Good afternoon,
We are using 20 of the DP83867E on our board. We control 10 PHYs with one MDC-MDIO interface and 5 PHYs with another MDC MDIO interface and the other 5 with another MDC-MDIO interface. They are all controlled with the same FPGA.
These 20 PHYs are connected 20 other boards. We have the same PHYs there as well.
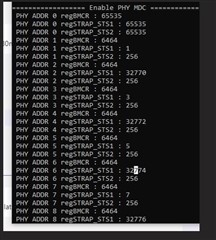
Sometimes at start-up, one or more of the links are not connected and once we try to read the ID of the PHY, we read all the register from the PHYs FFFF . We tried to disable and enable the PHY (using the power down pins) that are not working properly and we see the issue is still there, and a power cycle will often solve the issue (and we can read correct data from PHY again).
Can you please tell us which possible scenarios may block the PHYs and lead to read FFF from MDIO ?
We investigate the issue further, and we have some remarks may help you to give some feedback to us.
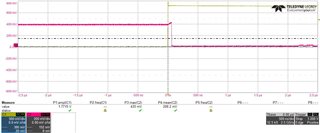
1-) We use the 3 supply mode and we enable 1V8 and 2V5 supplies at the same time. But 1V8 reaches the operational minimum limit of the PHY (1.71V) around 70us earlier than 2V5 operational minimum range(2.375).
2-) We give no reset to PHY from the FPGA and reset signal is pulled up with 1V8 rail which is IO Voltage level.
3-) I also see there is a power down requirement which says When powering down the DP83867, the 1.8-V supply should be brought down before the 2.5-V supply. Brought down means out of the operational limits or down to 0V or something else?


Pictures are power-up and power down scenarios of 1V8 and 2V5. If you cant see the pictures clearly, I can send an e-mail.
If you think some other measurements may help to investigate more, please let us know.
Best regards,
Onur Kusakoglu