


Part Number: TCAN1144-Q1
Other Parts Discussed in Thread: TCAN1145EVM
Hello,
I have been testing the TCAN1144 and prototyping implementing it into some existing hardware.
The bus fault detection functionality it being tested via a custom spidev program which polls the INTCANBUS register every 1 second and reports the status of the faults.
It has successfully been able to detect all the faults its says it can with the exception of CANLGND which it detects sporadically. Also every now and again it falsely detects half termination.
The chip is configured like so, with INH and wake being pulled to GND as they are unused.
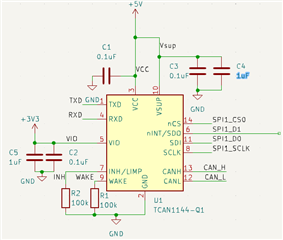
However, the power, spi ,and can connections all break off from a breakout board and are soldered to pads of a pre-existing PCB so the setup is less than savory.
The can bus that the transceiver is being tested on is rather short in length so this shouldn't be the issue.
Previously the chip was tested with a TCAN1145EVM where the TX, RX & SPI wires were fed to the EVM from the pre-existing PCB and it was found to work reasonably reliably. But with the new setup, this is not the case.
Any Ideas on what sort of difference/conditions could cause the chip to be behaving unreliably when detecting this error?
Kind regards,
Max


