Part Number: TCAN4550
Tool/software:
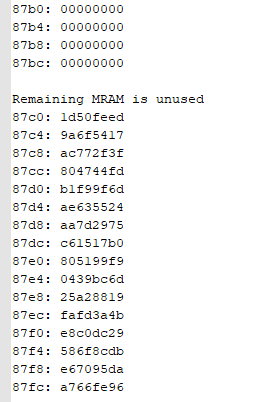
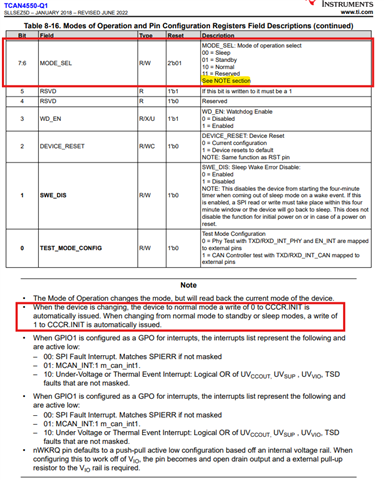
When I was testing can communication here, I soon found that after sending a command to the slave device, there was no data return from the slave device. At this point, I checked the interrupt nINT pin of tcan4550 and found that it was always at a low level. The chip should be abnormal.
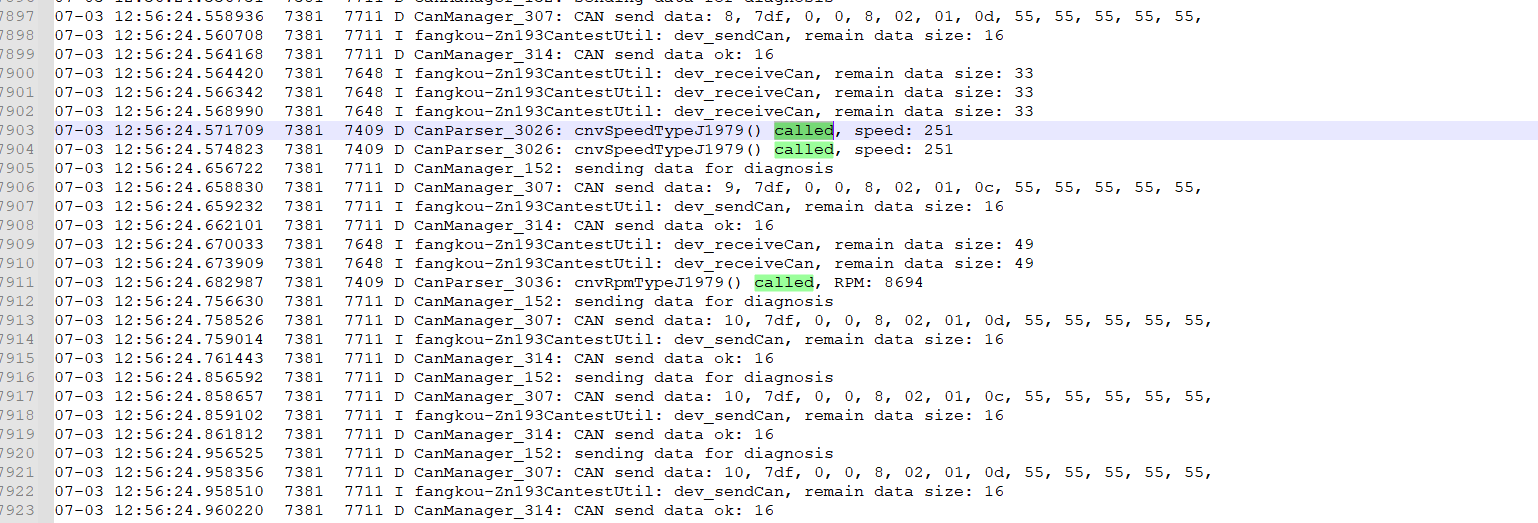
The can command was sent 10 times. From the 0th to the 9th time, the slave device could reply with the data. After the 10th time, the slave device no longer replied with the can data.


I'm extremely anxious. Please help me figure out what the problem is and how to solve it