


Other Parts Discussed in Thread: TLK110
Hi all!
I'm testing ethercat communication in a custom board (broad cut&paste from ICE demo board). Everything is fine, except for frequent RX error at physical TLK110.
Ethercat diagnostic tools report "frame lost" increasing count.
I've tried these:
- decrease distance between PHY and MAGNETIC (less than 5mm)
- change terminating resistors values ( slightly less and more than 50Ohm)
- increase bypass capacitors value
- change magnetic type and manufacturer
- change Ethercat master
I can't see any valuable difference in data error rate.
I've double checked resistor values, clock signals, pull up/down, with no result.
Here you can see a oscilloscope dump when an RX error occurs:
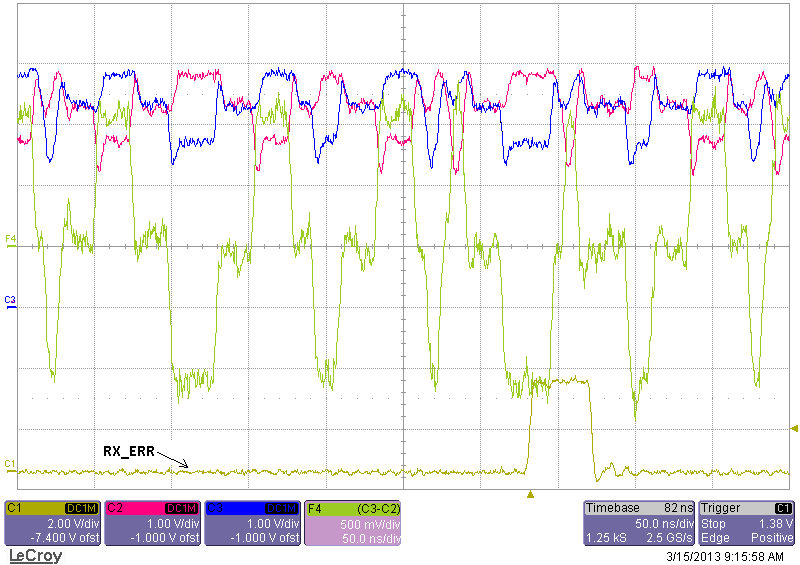
RX_ERR in channel 1 is pin 41 output signal. Channel 2 and 3 are RX+ and RX- signals. Trace F4 is the difference between RX+ and RX-
Differential signal seems fine to me.
This problem is going to be a BIG issue. Any suggestions?



{kind=link}