


Part Number: AM2432
Tool/software:
Hello,
Take this OSPI flash as example. in the read timing figure, there are several sequenced data cycle after command, address, dummy cycle. In this way can read in multiple data in burst automatically.
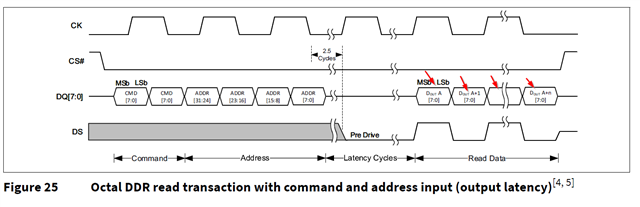
Also captured similar waveform on board.
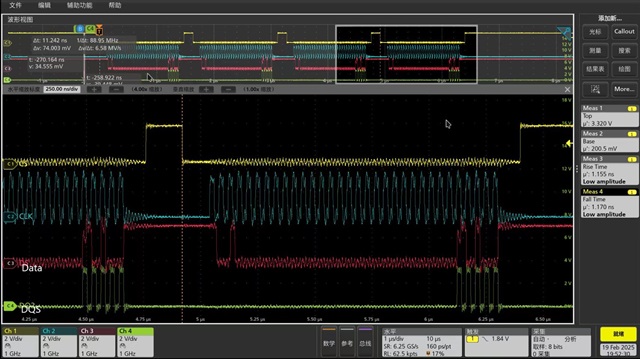
But seems the burst read is not be used by software.
When read 10 byte data in software, OSPI output 10 CS, each CS period has command, address, dummy cycle, and 5 DQS cycle.
If read 8 byte data, then output 8 CS period.
deep look into code, software use memcpy to read, OSPI should be in memory map mode already.
From the waveform, as there are 5 DQS signal, flash output 10 byte data within one CS period already, but software don't know, still read byte by byte.
With this timing behavior, the throughput is very poor, waste too many cycles, even lower than single line SPI as it has not dummy cycle required.
#1. How to utilize the sequence read to increase throughput? Can only use DMA to utilize the sequency burst read?
#2. Is the 5 DQS configurable? we saw it is always 5 sequence pulse no matter how many byte to read.

