


Part Number: MSP432P4111
G'Day all,
Sorry, for this long complicated email. We've been working on a difficult bug in our system for a while now and think we've finally tracked the root cause. We think its an issue with SYSBIOS but we don't discount the possibility we are abusing SYSBIOS is some way that we don't understand. Given that we think this is a SYSBIOS issue, things get a bit complicated....
For a while now (e.g. see this old forum post of ours, and this more recent post) we've had a problem where SYSBIOS occasionally gets upset and does not properly process time delays (e.g. clock functions set to run some time in the future or Task_sleep()).
The exact manifestation of this varies (our older post illustrates 3 variations using execution graphs) - but at the core what we see is that is that there are extended blocks of time (our testing says its about 2 seconds) where anything that is waiting on SYSBIOS timing doesn't run even though we expect it should. This is usually preceded by a period of time where Swi.ti_sysbios_knl_Clock_workFuncDynamic__E() runs for what seems an excessively long period.
We think we have found the root cause of this and would appreciate if you could confirm our observations using the attached example project that illustrates the issue.
Long story short:
- If we configure our project with the "Internally configure a Timer to periodically call Clock_tick()" option selected in the clock module settings, the project is built using TimerA0 with a 32768Hz clock input. In this case, we see the problem occur.
- If we configure our project with the "Application code calls Clock_tick()" option selected (and we call Clock_tick() in our own timer interrupt running off TimerA3 with a 1MHz clock input synchronous to MCLK) we never see the problem occur.
Our suspicion is that something goes wrong with the Timer_getCount() function in SYSBIOS when an asynchronous clock is used to drive the underlying timer.
The example project is simply a clock function and a timer HWI running with fairly short intervals toggling pins.
- runs on a MSP-EXP432P4111 Launchpad.
- Built using CCS9 compiler v18.12.4.LTS (and also CCS10, compiler v20.2.2.LTS)
- Built against Simplelink v3.40.1.02, XDCTools 3.60.2.34
Now
- Build the project as given (note MCLK = 48MHz). In this case the project is configured with the "Internally configure a Timer to periodically call Clock_tick()" option selected.
- freeze all timer modules (CCS -> Scripts menu -> MSP432 Debug Clock Control - > Freeze all timer modules)
- Open the file [SIMPLELINK]\kernel\tirtos\packages\ti\sysbios\family\arm\msp432\Timer.c and put a breakpoint at line 252
- Start debugging and wait until you hit the breakpoint - this can take a few seconds or a few hours.
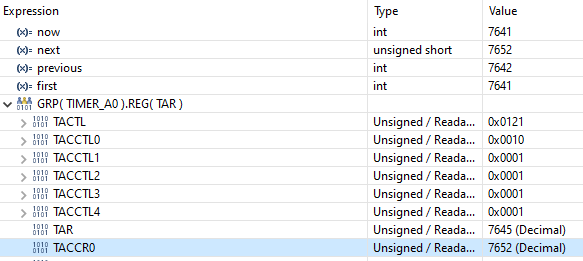
- A screen shot of debugger output when we hit the breakpoint is attached below.
The code at the breakpoint is intended to deal with timer rollovers, but it's been triggered when the timer is well away from rolling over.
- The variable first comes from the Timer_getCount() function call at line 245. The function is inlined by the optimizer so first is in scope at line 252.
- The variable now is equal to the output of Timer_getCount() (which returns the value of first) as would be expected.
- The register TACCR0 has been set to the value of variable next as expected (per line 185).
- The variable previous is equal to the last value of the TACCR0 register.
If previous stores when the last value of the CCR0 register, then by definition now should be larger (unless a roll over has occurred). But when we hit the breakpoint now is smaller than previous even though no rollover has occurred. This seems wrong, and when this happens we get our behavior where SYSBIOS does not run anything waiting on a timer.
If you change our code over so that Clock_tick() is called by our interrupt (see comments at line 173 in hello.c) you'll see that you never hit the breakpoint (unless you happen to catch a rollover) even after many hours of running, so whatever the problem is, its seems specific either to TimerA0 or specific to a TimerA module using an asynchronous clock input.
Cheers
Julian
