Part Number: TM4C129XNCZAD
Hi,
We've been recently encountering an unexpected issue regarding the use of the hardware CRC.
Our code is quite simple and has been tested without any trouble....
// Write the control register with the configuration
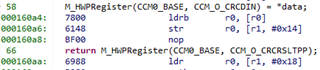
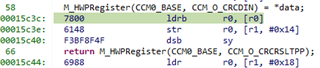
M_HWPRegister(CCM0_BASE, CCM_O_CRCCTRL) = (CRC_CFG_INIT_1 |
CRC_CFG_SIZE_8BIT |
CRC_CFG_TYPE_P1021);
// Feed the CRC module with data
while (length-- != 0u)
{
M_HWPRegister(CCM0_BASE, CCM_O_CRCDIN) = *bytes++;
}
// Return post processed value
return M_HWPRegister(CCM0_BASE, CCM_O_CRCRSLTPP);
.... until we applied the -O2 optimization.
Once the -O2 optimization was applied, we check the assembly code which is correct but the calculated CRC was different when running the code and when going step by step in assembly.
After further investigation, the CRC was correct when going by step but when running the code, the returned CRC was the one of the length-1 first bytes of the array and in this case, when halting the processor, the correct CRC was contained in the CCM0 module register, contrary to what was returned by the function.
Quotes from the datasheet:
" CRCs are computed combinatorially in one clock."
" Because CRC calculations are a single cycle, as soon as data is written to CRC Data Input (CRCDIN) register, the result of CRC/CSUM is updated in the CRC SEED/Context (CRCSEED) register, offset 0x410."
Is this incorrect? Is there an undocumented timing when reading the CRC Post Processing Result (CRCRSLTPP) register? How can a CRC calculation take one cycle and not a XOR or a bit reverse?
We added a NOP instruction between the last written byte and the read of the post processing result and it seems to work. However, as we are working in a medical device company, this is an unacceptable patch without providing any additional information to justify it.
Best regards,
Matthieu Tardivon