Other Parts Discussed in Thread: HALCOGEN
Hi there,
I had a few technical questions regarding the implementation of the SafeTI Library and other safety features with the LS31HDK.
- What is the test coverage of the CPU self-test / STC test? I can find how to implement it but I'm not actually sure what tests it does on the CPU.
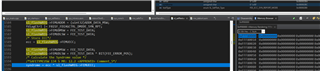
- How are the tests meant to be integrated with HALCoGen? In the SL_SelfTest_SRAM SRAM_ECC_ERROR_FORCING_2BIT test, I'm finding that the test is failing because the ESM status register (ESMSR3) is being cleared inside of the _dabort routine generated by default in HALCoGen. I cannot remove the statements that clear SR3 in the _dabort without causing the tests in sys_startup.c to fail. I know error handling is supposed to be outside the scope of the SafeTI library but the example exception handler provided there doesn't do any actual handling, it just tries to mask the abort.
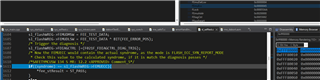
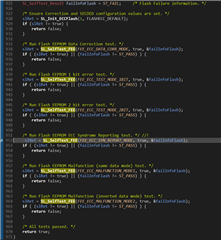
- In the SL_SelfTest_FEE FEE_ECC_SYN_REPORT_MODE test, I'm finding that the test fails because the syndrome value calculated by the library (NOT the one calculated by the MCU itself) is incorrect. Following the reference manual, the syndrome value the MCU calculates is 0x45, which is expected for a multibit failure. However, the SafeTI calculated value (which is then used for a comparison between the two) is always calculated as 0. Is this a bug?